 On November 18, 2025, Cloudflare, a company that sits in front of a huge share of the world’s web traffic, took a substantial part of the Internet down with it.
This was not a record-breaking DDoS, not a zero‑day exploit, and not a nation‑state attack. It was a database configuration change, a feature file that quietly doubled in size, and a
On November 18, 2025, Cloudflare, a company that sits in front of a huge share of the world’s web traffic, took a substantial part of the Internet down with it.
This was not a record-breaking DDoS, not a zero‑day exploit, and not a nation‑state attack. It was a database configuration change, a feature file that quietly doubled in size, and a Rust unwrap() in production code that assumed “this will never happen”.
 Cloudflare has published a detailed post‑mortem on the incident, including exact timings and technical details in its official report, Cloudflare outage on November 18, 2025. A separate long‑form analysis from MGX, The Cloudflare Global Outage of November 18, 2025: An In-Depth Analysis, reconstructs the wider business impact and contextualizes it against other Internet outages.
This article focuses on the core question many engineers, SREs, and technical leaders will be asking:
Cloudflare has published a detailed post‑mortem on the incident, including exact timings and technical details in its official report, Cloudflare outage on November 18, 2025. A separate long‑form analysis from MGX, The Cloudflare Global Outage of November 18, 2025: An In-Depth Analysis, reconstructs the wider business impact and contextualizes it against other Internet outages.
This article focuses on the core question many engineers, SREs, and technical leaders will be asking:
How did a database permission change and a single module in Cloudflare’s proxy engine end up breaking a significant fraction of the global web, and what are the practical lessons for people who build and operate systems on top of Cloudflare?
1. The outage in plain terms
According to Cloudflare’s own report, the incident began at 11:20 UTC on November 18, 2025. At that time, Cloudflare’s network started failing to deliver core HTTP traffic, returning a flood of 5xx errors to end users. For anyone trying to access a site behind Cloudflare, the symptom was simple: error pages instead of content.
The period of major impact lasted roughly three hours, from 11:20 to about 14:30 UTC, when “core traffic was largely flowing as normal” again. Full restoration of all systems took until 17:06 UTC (Cloudflare post‑mortem).
During that window:
- Core CDN traffic returned
5xxresponses at an abnormal rate. - Authentication via Cloudflare Access failed in large numbers.
- Turnstile, used for login flows and anti‑abuse checks, could not load reliably.
- Workers KV saw elevated
5xxbecause its front‑end gateway depended on the failing core proxy. - Cloudflare’s own dashboard login was effectively blocked for most users because Turnstile never loaded.
From the perspective of users and businesses:
- Many people first blamed their local connection before realizing the problem was widespread.
- Websites across social, AI, e‑commerce, media, and finance sectors became partially or completely unreachable.
- Even Cloudflare’s independent status page briefly went down, by coincidence, which initially reinforced the suspicion of an attack.
External coverage from outlets like Reuters and Network World quickly converged on the same picture: this was a broad, multi‑hour degradation of a major piece of Internet infrastructure.
Cloudflare, for its part, was clear on one point: this was not a cyber attack. It was a failure of its own systems.
2. What actually failed inside Cloudflare
To understand why this particular outage is instructive, it helps to look at how Cloudflare processes HTTP requests and where the failure occurred.
Every HTTP request to Cloudflare passes through several layers:
- TLS / HTTP termination.
- A core proxy service (known internally as FL or FL2).
- Additional modules for caching, routing, and enforcement of customer policies (WAF rules, DDoS controls, bot management, access control, etc.).
The Bot Management module sits inside this path. It scores each request based on a set of features, which are stored in a configuration file that is:
- Generated every few minutes from a ClickHouse cluster.
- Distributed to Cloudflare’s fleet of edge servers around the world.
- Used by the machine‑learning model to decide how likely a request is to be automated.
On November 18, the failure started here.
2.1 A ClickHouse permission change with unintended consequences
As part of an ongoing effort to improve security and reliability of distributed queries on its ClickHouse clusters, Cloudflare changed how access permissions were handled.
Before the change:
- Queries that read metadata from
system.columnsonly saw tables in thedefaultdatabase. - A query like:
After the permission change:
- Users (or in this case, a system account) were granted explicit access to metadata in an additional backing database,
r0, which holds the underlying tables for distributed queries. - The same query, now that
r0was visible, returned duplicate columns — effectively more than doubling the number of rows in the result set.
That query output was not just for diagnostics. It was feeding directly into the logic that constructs the Bot Management feature file.
In other words:
- Before the change, the feature configuration file had a stable size and a predictable number of features.
- After the change, the file suddenly contained more than twice as many features, due to duplicated metadata rows from
r0.
Cloudflare’s own description of this behavior is in the “Query behaviour change” section of its post‑mortem (Cloudflare outage report).
2.2 A feature file that silently “got fat”
The Bot Management feature file is regenerated every few minutes and pushed across Cloudflare’s network.
This is intentional: the system needs to react quickly to new patterns in bot traffic.
Two conditions combined to make this routine operation dangerous:
- The file format allowed the number of features to change based on what the database returned.
- There was no strict validation layer treating this internally generated file as untrusted input.
When the query started to see extra rows, the feature file grew suddenly and unexpectedly. From the outside, nothing looked particularly alarming: it was still “just” another configuration file being pushed across the network.
Internally, however, it crossed a boundary that the proxy’s Bot Management code was not prepared to handle.
2.3 A Rust unwrap() in the wrong place
Inside Cloudflare’s new proxy engine (FL2), Bot Management has a limit on how many features it will handle at runtime. The limit exists mainly for memory preallocation and performance reasons. Cloudflare notes that:
- The limit was set to 200 features.
- In practice, they had been using around 60 features.
When the enlarged file with more than 200 features arrived, it hit that limit. Instead of handling the overflow gracefully, the Rust code checked the limit and then used Result::unwrap() on an error path. The error was not treated as something that could happen in production.
The runtime consequence was blunt:
thread fl2_worker_thread panicked: called Result::unwrap() on an Err value
In a module that runs inside the core proxy, a panic of this kind is not contained. It caused the process handling HTTP traffic to fail, which translated directly into 5xx responses for user requests.
On older proxy instances (FL), the behavior was different but still incorrect: bot scores were not computed correctly and effectively defaulted to zero, which could cause rules that rely on bot scores to misbehave. On the newer FL2 engine, Cloudflare customers saw explicit HTTP errors.
The undermining point is simple: a hard limit, plus a silent change in input, plus an unchecked assumption in code, produced a global outage.
3. Why were the symptoms confusing
If this had been a simple “bad configuration deployed once”, the failure would likely have been sharp and monotonic. Instead, the first phase of the outage looked irregular.
There were two reasons for that.
First, the feature file was regenerated every five minutes by a query against a ClickHouse cluster that was being upgraded gradually:
- Some nodes had the new permission behavior and returned the enlarged result set.
- Others had not yet been updated and continued returning the original, smaller dataset.
Every five minutes, depending on which nodes the distributed query touched, the generated feature file could be “good” or “bad”. The file was then rapidly propagated across Cloudflare’s fleet.
The result was a saw‑tooth pattern:
- For some intervals, the system recovered when a “good” file was distributed.
- A few minutes later, it failed again when a “bad” file took over.
Cloudflare’s chart of global
5xxrates in its post‑mortem shows this oscillation clearly (Cloudflare outage report).
Second, by coincidence, Cloudflare’s own status page, which is hosted off Cloudflare’s main infrastructure, also encountered problems around the same time. The bot feature file issue did not cause that independent failure. But seeing both Cloudflare’s network and its status page behave erratically led part of the incident response team to initially suspect a large‑scale distributed attack, rather than an internal software bug.
This confusion is reflected in contemporaneous coverage and technical community discussions aggregated in the MGX report (MGX in‑depth analysis).
The combination of intermittent recovery, increasing 5xx volume, and unrelated status page issues meant the first hour of diagnosis had to wrestle with misleading signals.
4. Scope of impact: services and users
It is easy to treat “Cloudflare outage” as an abstract headline. The practical consequences were concrete.
Cloudflare itself listed the services directly affected:
- Core CDN and security services returning
5xxerrors. - Turnstile failing to load, breaking login flows.
- Workers KV returning
5xxbecause its requests depended on the failing core proxy. - Dashboard logins failing for most users, due to Turnstile being down.
- Email Security temporarily losing access to an IP reputation source, reducing spam detection accuracy.
- Access suffering widespread authentication failures; sessions could not be established, though existing sessions remained valid.
From the customer side, the MGX analysis traces the outage across a wide variety of prominent services, using reports from status pages, social media, and monitoring tools such as Cloudflare Status and Downdetector. These include, among others:
- Social and communication platforms (X, Discord, Zoom).
- Major AI services (ChatGPT, Claude, Gemini, Perplexity).
- Creative and collaboration tools (Canva, Figma, Atlassian tools, 1Password).
- E‑commerce and financial platforms (Shopify, Coinbase, Uber, Square, IKEA’s online presence).
- Critical public‑facing systems (for example, a regional transit authority site).
Reports from Network World and others describe the impact as global: users on multiple continents saw sites time out or return 500 errors at the same moment.
The outage also had an ironic side effect: even websites designed to report outages, such as Downdetector, were affected because they themselves depended on Cloudflare for delivery.
5. Economic and operational consequences
Cloudflare has not attempted to put a precise dollar figure on the incident. That would be nearly impossible given the diversity of affected businesses. The MGX report takes a different angle and uses standard industry data on the cost of downtime:
- Large enterprises frequently report losses in the range of USD 5,600 to 9,000 per minute of unplanned downtime.
- Surveys cited by MGX indicate roughly 93% of enterprises estimate downtime costs above USD 300,000 per hour, and nearly half report costs above USD 1 million per hour for serious outages.
Those figures are consistent with broader vendor and analyst studies on outage costs and are used here only as scale indicators, not as exact accounting. Given:
- The major impact window of about 3+ hours.
- The fact that Cloudflare front‑ends a double‑digit percentage of the world’s websites — Cloudflare itself notes its role in handling a large fraction of Internet HTTP traffic in marketing and technical material such as Cloudflare Radar.
- The heavy concentration of high‑traffic services among affected sites.
It is not unreasonable to say that the aggregate global economic impact likely sat somewhere in the hundreds of millions of dollars. That estimate, again, follows the reasoning in the MGX in‑depth analysis, which cross‑references public outage data and standard downtime cost models.
Beyond direct revenue loss, several secondary effects are worth noting:
- User trust and return rates: there is extensive research (not specific to this incident) showing that a significant percentage of users do not return quickly to a site after a poor experience.
- SEO and availability: extended periods where a site returns 5xx can negatively affect search engines’ perception of reliability, especially if repeated. -** Support load**: for many organizations, outages of this kind translate immediately into an overloaded support queue, with users asking “is it just me?”, even though the root cause lies at the infrastructure provider.
None of these are unique to Cloudflare. They occur when a central dependency fails.
6. How Cloudflare contained and resolved it
Cloudflare’s resolution sequence is documented in its own timeline and expanded on by MGX. The key steps are:
- Investigation and early mitigations
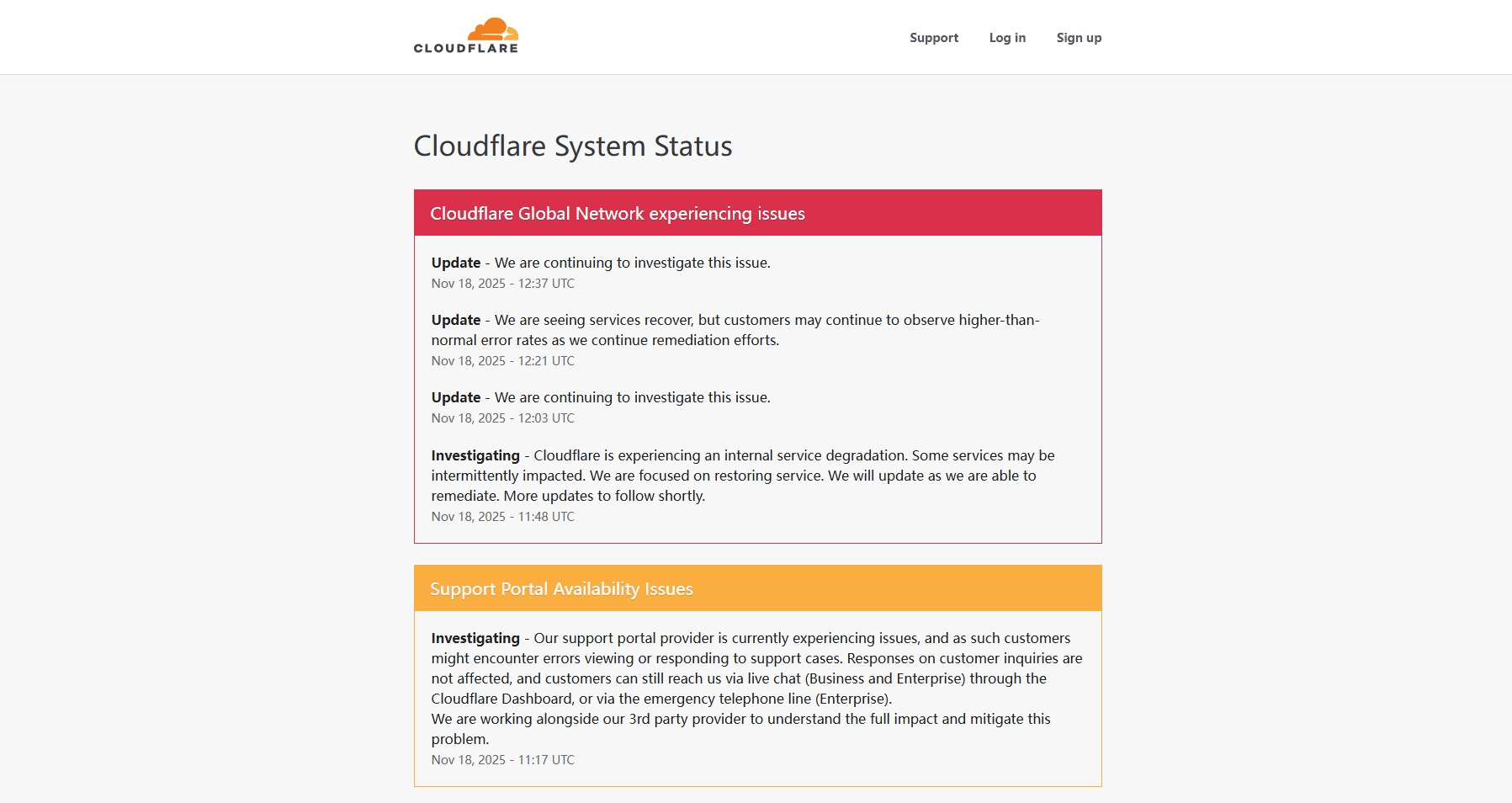
- Automated tests detected elevated errors around 11:31 UTC, followed by manual investigation. An internal incident call was initiated at 11:35 UTC.
- For a period, engineers focused on Workers KV, which showed elevated errors and appeared, from some angles, to be the primary problem. Mitigations such as traffic manipulation and account limiting were attempted to bring KV back into a normal operating envelope.
- Bypassing the new proxy path
- Around 13:05 UTC, Cloudflare implemented internal bypasses so that Workers KV and Access would fall back to an earlier version of the core proxy (FL instead of FL2). While the underlying bot configuration issue still existed there, the impact was less severe: bot scores were wrong, but the proxy itself did not panic.
- This did not fully resolve the customer‑facing issues, but it reduced their scope.
- Identifying the Bot Management configuration as the trigger
- By about 13:37 UTC, attention had shifted from individual services to the Bot Management feature file as the common factor behind the errors. Engineers converged on the feature file generation pipeline as the most likely trigger for the cascade of failures.
- Stopping propagation and inserting a known good file
- At 14:24 UTC, Cloudflare halted the automatic creation and propagation of new Bot Management configuration files. They then manually inserted a last‑known‑good version of the feature file into the distribution queue.
- After testing that this corrected file restored normal behavior in targeted environments, Cloudflare deployed it globally.
- Restarting affected services
- With the good file in place, Cloudflare forced restarts of the core proxy services. This cleared out bad state and ensured that all running processes were consuming the corrected configuration.
- According to Cloudflare, core traffic was largely back to normal by 14:30 UTC, and by 17:06 UTC all services were considered fully restored (Cloudflare post‑mortem timeline).
- Post‑incident work
- Cloudflare has outlined several follow‑up efforts:
- Treating internally generated configuration with the same suspicion as user‑generated input, with validation and safety checks.
- Adding or strengthening global kill switches for features.
- Ensuring that crash dumps or error reports cannot saturate resources during an incident.
- Reviewing failure modes of core proxy modules, especially around hard limits and panic paths.
These steps are consistent with a recurring theme in prior outages, both at Cloudflare and elsewhere: the hard part is rarely “find the bug” alone; it is about building mechanisms that limit blast radius, make rollback fast, and prevent diagnostic tools from becoming part of the problem.
7. What this incident says about Internet infrastructure
From a purely technical standpoint, this outage looks like a classic chain of events:
- A configuration change in a database.
- A query that assumed its environment (only one database would be visible).
- A downstream system that implicitly trusted the result.
- A size limit that was never expected to be hit.
- A panic in production code instead of a controlled fallback.
Taken alone, none of these elements is exotic. What makes the incident important is that it happened at the scale of Cloudflare’s infrastructure.
Several broader observations follow.
7.1 Centralization is convenient and dangerous at the same time
Cloudflare, AWS, and similar providers make it dramatically easier to run secure, performant applications without building everything from scratch. The trade‑off is clear: when a single vendor fronts a large fraction of the world’s traffic, its failures become everyone’s failures.
Commentary in the MGX report and in articles such as “The Internet's Single Point of Failure: Cloudflare” highlights this tension. The efficiency of centralization brings with it a systemic risk: a localized bug can cause a synchronized global failure.
This is not an argument against using Cloudflare. It is a reminder that if your architecture assumes “Cloudflare is always there”, then by definition, Cloudflare is a single point of failure for you.
7.2 Automation amplifies both good and bad changes
The feature file pipeline that failed here is the same mechanism that normally allows Cloudflare to adapt quickly to new bot behavior. Automatic, frequent rollout of configuration is what gives Bot Management its responsiveness.
On November 18, the same mechanism became the amplifier for bad data. Every five minutes, the system propagated a configuration that was structurally valid but semantically broken.
This is a pattern seen in many outages, including the 2021 Fastly incident and previous Cloudflare events documented in Details of the Cloudflare outage on July 2, 2019 and other post‑mortems:
- Automation is necessary at scale.
- Automation without strict validation and staged rollouts can turn a small mistake into an immediate, global problem.
7.3 “Latent bugs” are only dormant until someone touches the right switch
Cloudflare’s own language in interviews and coverage, such as TechCrunch’s summary of the incident, describes the Rust bug as “latent”: the defective unwrap() call had been present in code, but never exercised under normal input conditions.
The database permission change did not “create” the bug. It created input that finally reached the unprotected branch.
Every large codebase contains such paths. The practical lesson is not that latent bugs can be eliminated entirely, but that defensive boundaries — type checks, explicit guards, input validation, limits, and staged rollout — are the difference between a latent bug being a theoretical problem and it becoming headline news.
8. Practical takeaways if you depend on Cloudflare (or anything like it)
This article is not about assigning blame to Cloudflare. They have published one of the more technically candid post‑mortems in recent memory, and the bug they uncovered is of the sort that could exist in any sufficiently complex system.
For teams that rely on Cloudflare, there are, however, several sober conclusions:
- Treat your provider as a dependency, not a constant
- If your architecture cannot function at all when Cloudflare is impaired, then Cloudflare is a critical dependency. That is not inherently wrong, but it should be recognized and managed explicitly.
- The MGX report’s section on strategies for resilience surveys patterns such as multi‑CDN, multiple DNS providers, and regional failover (MGX resilience strategies). Even simple DNS‑level escape hatches, tested periodically, can make the difference between “fully offline” and “degraded but reachable”.
- Make availability visible beyond your own perimeter
- During this incident, many organizations only realized they were affected because internal users complained or external customers reported failures. A more robust approach is to have synthetic monitoring that originates from multiple regions and networks, hitting public endpoints exactly as a normal user would, and recording status independently of Cloudflare’s own views.
- Cloudflare’s own Cloudflare Radar is a useful public view of broad Internet conditions, but it does not replace monitoring under your own control.
- Assume configuration can go wrong, even if you do not own it
- The feature file bug was fully within Cloudflare. Customers had no way to see or validate it.
- Nevertheless, you can design your own configuration systems with the same mindset Cloudflare now emphasizes: treat all generated configuration — even if produced by your own code — as untrusted until it has passed checks. That includes:
- Schema validation.
- Size and cardinality checks.
- Canary rollout.
- Explicit kill switches.
- Cloudflare is now applying those disciplines more aggressively to its own pipelines, according to its post‑incident remediation list (Cloudflare remediation steps).
- Plan, document, and rehearse failure modes
- The worst time to discover that you do not know how to operate your system without Cloudflare is while Cloudflare is down.
- Basic questions to answer in advance:
- If Cloudflare starts returning 5xx, how do you confirm that the problem is not in your origin?
- Do you have a clear, documented process for switching DNS or traffic to an alternative front end, even if limited?
- Have you ever tested that process under time pressure?
- These are not new ideas. They recur in discussions after many large outages, including prior Cloudflare incidents and the widely discussed AWS regional failures documented by providers and media like Network World. The November 18 event is simply another strong reminder.
Closing
The November 18, 2025 Cloudflare outage was not the result of a sophisticated attacker. It was the result of a configuration change, an unfiltered query, a growing feature file, and a panic in code that guarded a hard limit.
The scale of Cloudflare’s role on the Internet turned that sequence into a global disruption. The technical story, while specific in its details, follows a familiar pattern: assumptions about input, missing validation, automation that works until it suddenly does not.
For engineers and technical leaders, the value in Cloudflare’s post‑mortem and the subsequent independent analyses is not in pointing to a unique failure, but in recognizing a common set of fragilities in our own systems. If a database permission change and a single unwrap() can temporarily disable a significant slice of the web, it is worth asking which small levers in our own stacks could, under the right conditions, do the same.