OpenAI did not release GPT‑5.2 into a vacuum. The model landed in December 2025, weeks after Google shipped Gemini 3 Pro and Anthropic followed with Claude Opus 4.5 and Claude Sonnet 4.5. Internally, Sam Altman reportedly called a “code red” after Gemini 3’s launch, diverting resources back to core model quality and ChatGPT performance, as covered by both WIRED and Fortune.
So GPT‑5.2 is less a cosmetic update and more an attempt to answer one narrow question: can OpenAI retake the lead on difficult, professional work and agentic workflows?
This article takes a strict view: no hype, no vague “AI will change everything” claims. Instead:
- What GPT‑5.2 actually is, technically.
- How it stacks up against Gemini 3 Pro and Claude Sonnet 4.5 / Opus 4.5 on published benchmarks.
- Where each model is a sensible choice for real workloads.
- How to evaluate GPT‑5.2 in your own stack, including a path if you want to orchestrate it through MGX (MGX.dev).
Throughout, claims are grounded in primary sources: OpenAI’s own release notes and docs, MGX’s consolidated analysis of GPT‑5.2, and independent reporting from outlets like R&D World, Anthropic, Fortune, Fast Company, and the MGX deep‑dive itself at MGX.

1. What GPT‑5.2 Actually Is
OpenAI positions GPT‑5.2 as its “most capable model series yet for professional knowledge work,” with a clear emphasis on long‑running agents, coding, and structured tasks rather than new flashy features. The official announcement at OpenAI and the technical model docs at OpenAI API line up with the MGX analysis:
- Release date: 11 December 2025.
- Knowledge cutoff: 31 August 2025, meaning it tracks fairly recent technical and geopolitical events.
- Deployment: fully available in ChatGPT (Plus/Pro/Team/Enterprise) and via the API.
OpenAI splits GPT‑5.2 into three variants:
- GPT‑5.2 Instant (
gpt-5.2-chat-latest): tuned for speed, everyday ChatGPT tasks, a “warmer” conversational style, lighter reasoning. - GPT‑5.2 Thinking (
gpt-5.2): the workhorse for coding, math, and multi‑step projects, with heavier reasoning enabled by default. - GPT‑5.2 Pro (
gpt-5.2-pro): higher latency and cost, targeted at hard questions where small accuracy gains matter, such as complex scientific analysis.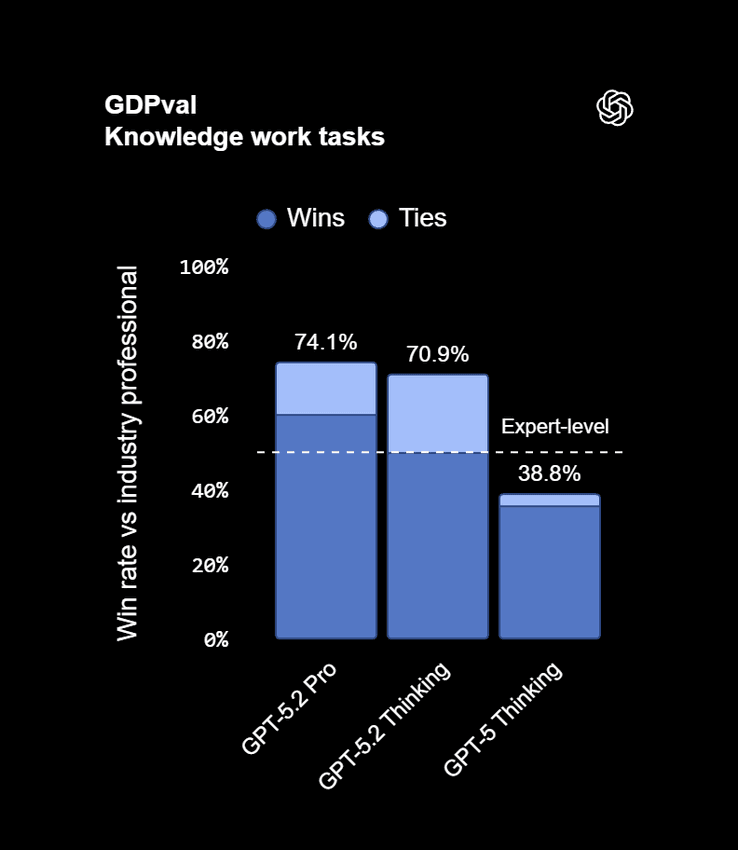
From a product standpoint, GPT‑5.2 is designed to be the default choice for:
- Spreadsheet and presentation automation.
- Deep software engineering assistance.
- Long‑context document analysis.
- Stable, tool‑heavy agent workflows. The explicit goal, supported by coverage in Fast Company and R&D World, is to meet or exceed Gemini 3 Pro and Anthropic’s frontier models on the same “hard benchmarks” that matter to enterprises.
2. Key Technical Changes in GPT‑5.2
2.1 Reasoning Tokens and Chain‑of‑Thought Routing
GPT‑5.2 extends the “reasoning token” ideas from OpenAI’s o1/o3 series into the main frontier model line:
- The MGX report, echoing the OpenAI docs, describes “Reasoning token support” and explicit chain‑of‑thought (CoT) passing between turns. Via the new Responses API, intermediate reasoning can be reused across calls instead of recomputed every time, improving both latency and cost (OpenAI API docs, MGX).
- Within ChatGPT, OpenAI now auto‑routes between Instant and Thinking modes: default to Instant, switch to deeper reasoning only when the task demands it (OpenAI Help Center).
Practically, this matters for:
- Math-heavy tasks that used to require manual “think step by step” prompting.
- Multi‑step coding problems where earlier partial reasoning is reused.
- Long chatbot sessions where the model previously “forgot” its own earlier rationale.
You still should not expect formal proof systems, but on benchmarks such as FrontierMath and ARC‑AGI‑2 the gains over GPT‑5.1 are large enough to matter in production.
2.2 Long‑Context and Memory
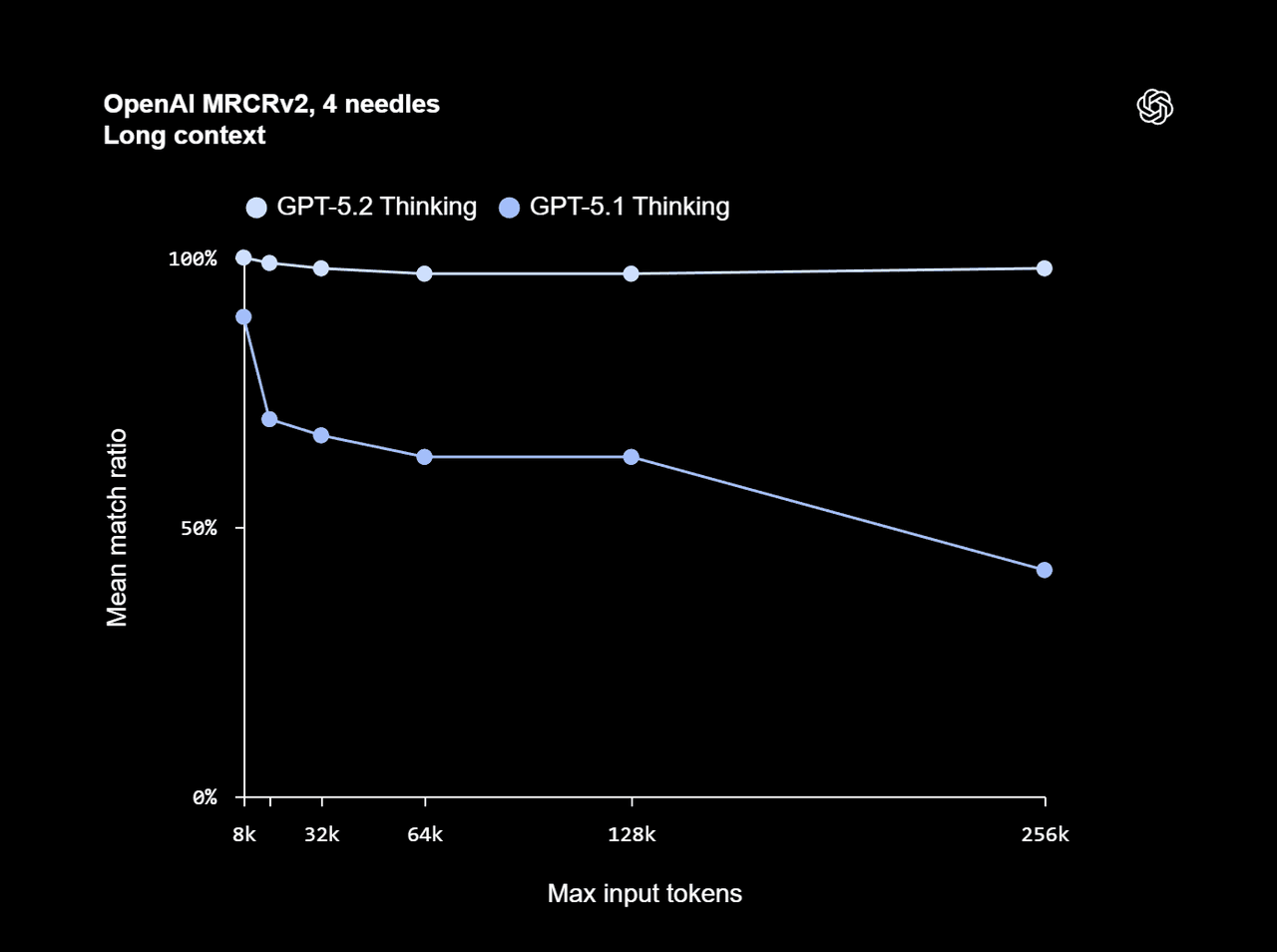
GPT‑5.2 does not chase Gemini’s raw context size of up to 1 million tokens. Instead, it aims at 400k tokens of usable context with much better retrieval and attention behavior:
- MGX reports that GPT‑5.2 Thinking reaches nearly 100% accuracy on the 4‑needle variant of MRCRv2 up to 256k tokens, a long‑context benchmark designed to stress retrieval across very large inputs.
- The maximum output length is 128k tokens, enough for entire draft reports or multi‑file code changes.
OpenAI’s own documentation emphasizes that the Responses + /compact endpoint can further extend effective context for tool‑heavy workflows by compacting intermediate chain‑of‑thought and tool outputs (OpenAI API docs).
In practice:
- GPT‑5.2 is tuned to lose track of details less often in long chats compared to GPT‑5.1, as summarized both by OpenAI and MGX.
- You can safely feed entire repositories, policy manuals, or case files, but you should still architect retrieval—dumping hundreds of thousands of tokens into every prompt is rarely the most reliable or economical approach.
2.3 Tool Use and Agent Workflows
Tool calling is where GPT‑5.2 tries to convert raw intelligence into reliable, multi‑step workflows:
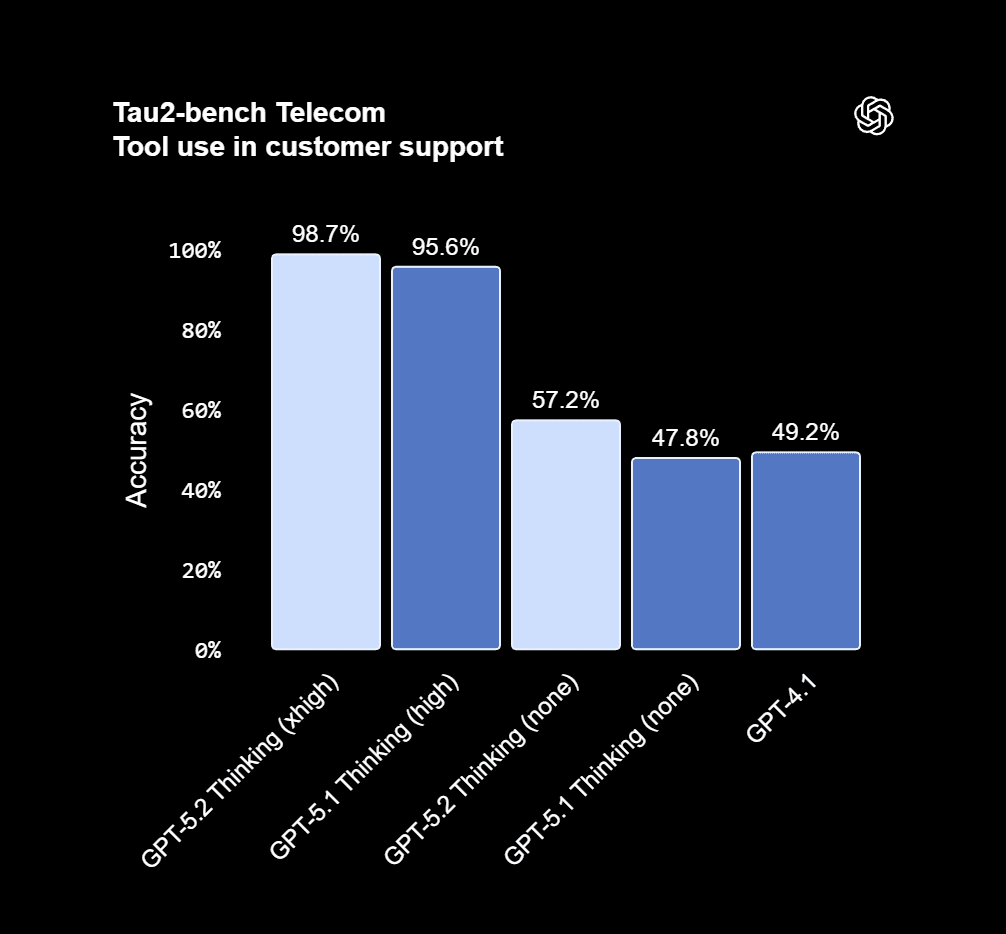
- On Tau2‑bench Telecom, a benchmark for tool‑driven customer support scenarios, GPT‑5.2 reportedly reaches 98.7% reliability on multi‑turn, multi‑tool tasks (MGX).
- OpenAI exposes new structured tools—such as
apply_patchfor code edits and a sandboxed shell interface—for “agentic coding” and operations tasks (OpenAI API docs). - Developers can now constrain outputs with context‑free grammars (CFGs) and limit available tools via
allowed_tools, giving more predictable behavior in critical pipelines.
OpenAI’s GDPval benchmark (44 occupations worth of “knowledge work”) is explicitly designed to measure whether this tool use and reasoning actually beat humans. On GDPval, GPT‑5.2 Thinking meets or exceeds expert human performance 70.9% of the time, versus 53.3% for Gemini 3 Pro and 59.6% for Claude Opus 4.5, according to Fortune’s coverage.
2.4 Vision and Multimodal Support
GPT‑5.2 does not introduce a brand‑new vision or image generation model. Instead, it focuses on harder visual reasoning:
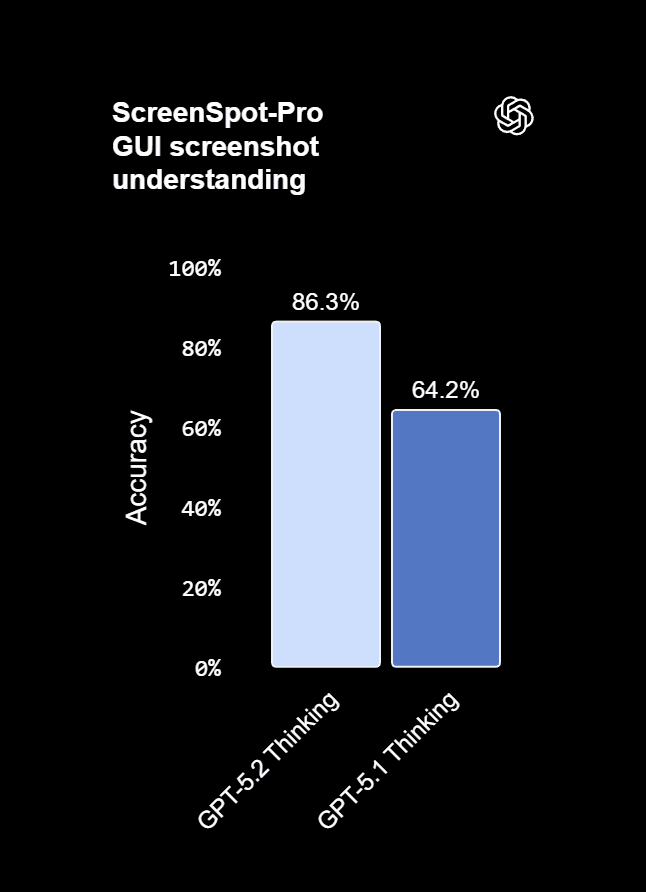
- MGX notes roughly halved error rates on chart reasoning and user interface comprehension compared to GPT‑5.1, plus stronger understanding of layout and relative positioning.
- Benchmarks like ScreenSpot‑Pro, which measure UI element recognition, show GPT‑5.2 Thinking at 86.3% vs 64.2% for GPT‑5.1 (MGX).
In other words: still not a visual AGI, but substantially more dependable for:
- Reading dashboards, charts, and reports.
- Walking through complex web interfaces in agent workflows.
- Understanding product screenshots and engineering diagrams.
Google likely still holds an edge on video and raw multimodal breadth, but for desktop‑style visual reasoning GPT‑5.2 is now competitive with the best public systems (R&D World).
2.5 Safety and Hallucinations
OpenAI claims, and MGX’s synthesis repeats, several measurable safety shifts:
- GPT‑5.2 Thinking hallucinates 30–38% less often than GPT‑5.1 on de‑identified factual queries.
- OpenAI continues its “safe completion” work for self‑harm, mental‑health, and emotionally dependent conversations, which WIRED and Fortune both highlight.
- An age‑prediction system is being rolled out to apply stronger protections for minors, with an optional “Adult Mode” planned for 2026.
Safety is a moving target, but two things are clear:
- GPT‑5.2 is less sycophantic and slightly more willing to say “I don’t know” or push back on unsafe requests.
- It is still capable of mistakes and biased outputs. External oversight remains non‑optional for high‑stakes deployments.
3. Benchmarks: GPT‑5.2 vs Gemini 3 Pro vs Claude Sonnet 4.5 / Opus 4.5
Benchmarks are imperfect, but they are the closest we have to a shared scoreboard. Below is a condensed view from MGX, OpenAI’s own data, and independent write‑ups in R&D World, Fast Company, Anthropic, and Caylent.
3.1 High‑Level Pattern
- GPT‑5.2 Thinking / Pro Clear gains in abstract reasoning, science, and professional tasks. Strong but not always dominant in coding.
- Gemini 3 Pro / Deep Think Very competitive in math and code, still strong on “Humanity’s Last Exam” and 1M‑token context. Better video and broad multimodality.
- Claude Sonnet 4.5 / Opus 4.5
Extremely strong on real‑world coding (SWE‑bench Verified) and computer use (OSWorld); Opus 4.5 is Anthropic’s high‑accuracy model, while Sonnet 4.5 is the workhorse for coding agents and long‑horizon tasks (Anthropic).
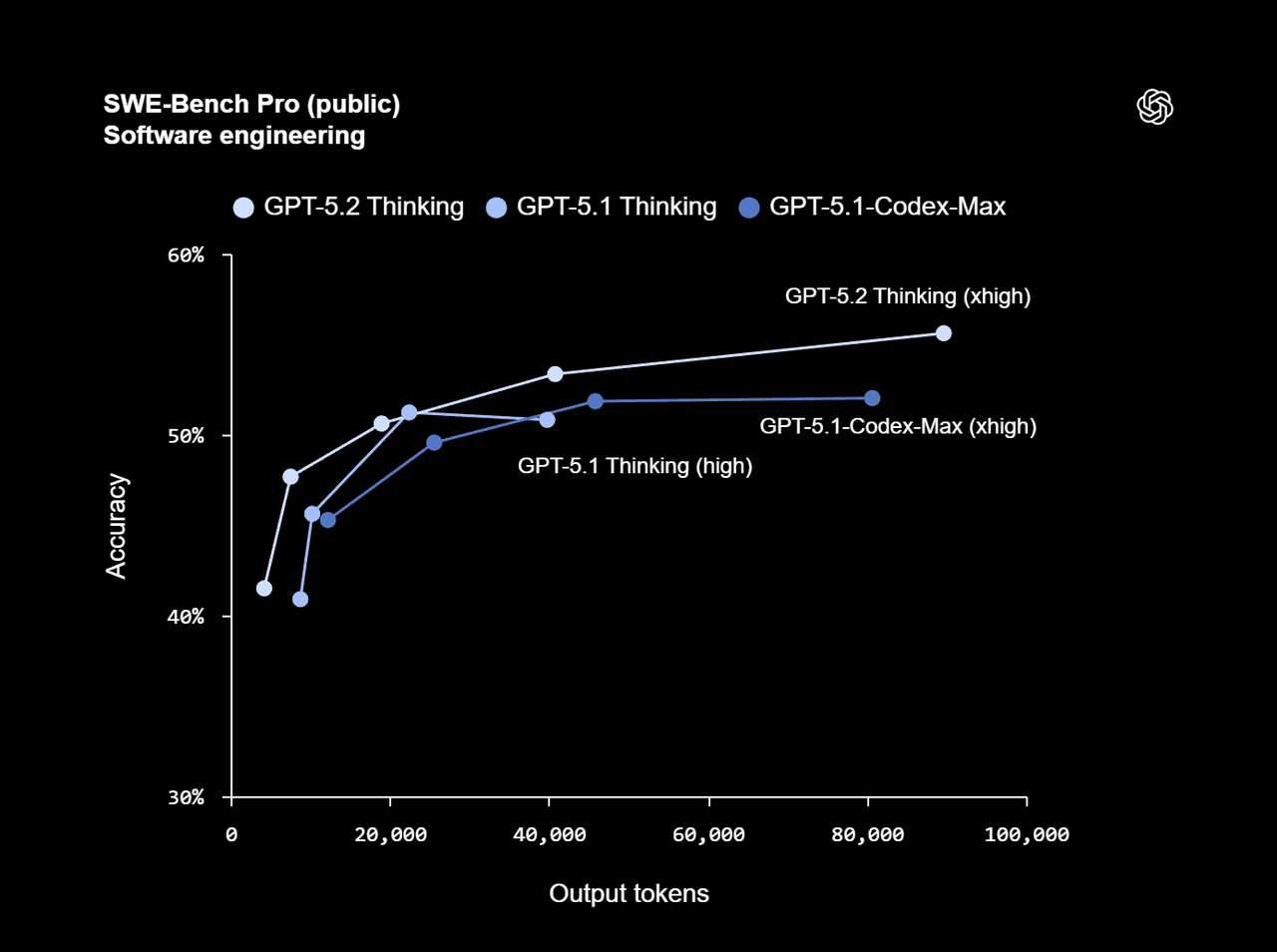
3.2 Representative Benchmarks
(Numbers are approximate and vendor‑reported unless otherwise noted. They should be read as signals, not gospel.)
Professional knowledge work – GDPval
- GPT‑5.2 Thinking: 70.9% win or tie vs human professionals across 44 occupations.
- Claude Opus 4.5: 59.6%.
- Gemini 3 Pro: 53.3%.
Source: Fortune’s summary of OpenAI’s data.
Interpretation: GPT‑5.2 is currently the strongest “office worker”: drafting documents, building spreadsheets, preparing presentations, and running multi‑step knowledge tasks.
Coding – SWE‑bench and SWE‑bench Pro
- SWE‑bench Pro (OpenAI’s agentic coding benchmark):
- GPT‑5.2 Thinking: 55.6%, new state of the art among models evaluated there, surpassing GPT‑5.1 and Gemini 3 Pro (MGX, Fast Company).
- SWE‑bench Verified (community benchmark against GitHub issues):
Interpretation: GPT‑5.2 is excellent at agentic coding inside OpenAI’s own scaffolding, while Claude Sonnet 4.5 currently sets the pace on community SWE‑bench Verified. If your workload is “LLM as a coding agent over large repos,” Sonnet 4.5 deserves serious attention alongside GPT‑5.2.
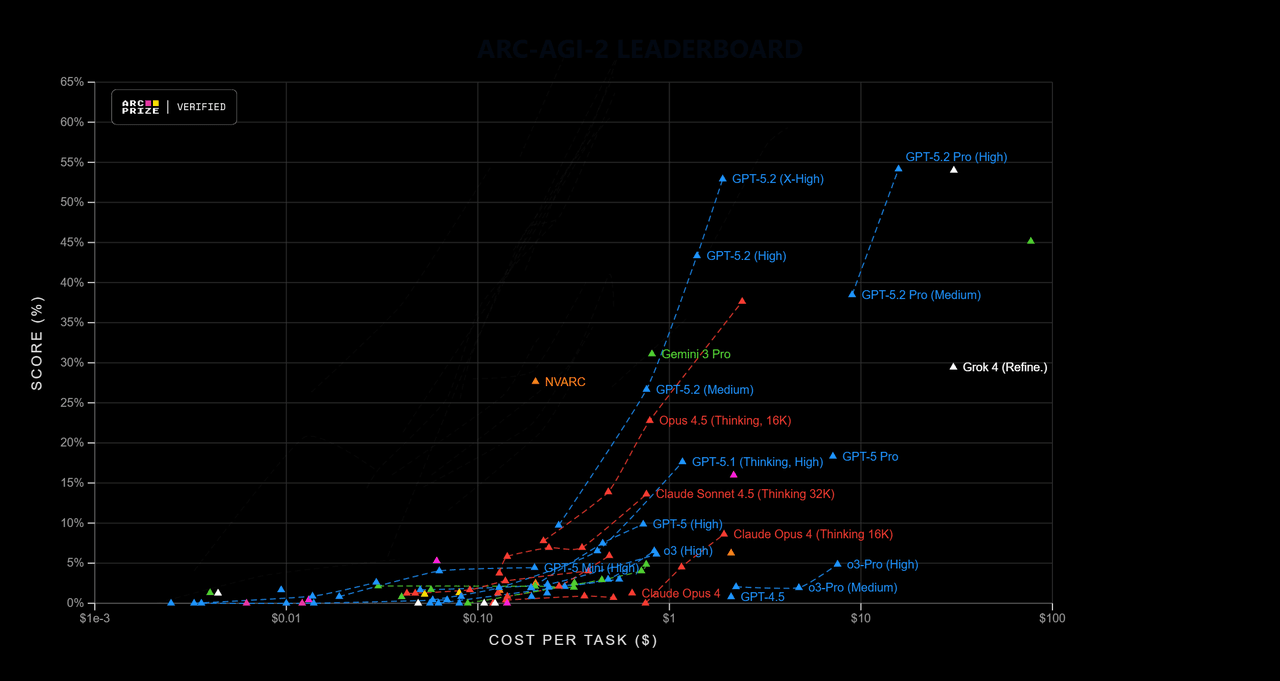
Abstract reasoning and science – ARC‑AGI, GPQA, AIME
From the R&D World comparison of GPT‑5.2, Gemini 3.0, and Claude Opus 4.5 (R&D World):
- ARC‑AGI‑2 (hard abstract reasoning):
- GPT‑5.2 Thinking: 52.9%
- GPT‑5.2 Pro: 54.2%
- Claude Opus 4.5: 37.6%
- Gemini 3 Deep Think: 45.1%
- GPQA Diamond (graduate‑level science):
- GPT‑5.2 Pro: 93.2%
- GPT‑5.2 Thinking: 92.4%
- Gemini 3 Deep Think: 93.8%
- Claude Opus 4.5: ~87%
- AIME 2025 (math, no tools):
- GPT‑5.2: 100% without tools.
- Gemini 3 Pro: 95% (with code execution).
Interpretation: GPT‑5.2 Thinking/Pro are among the strongest public models for abstract reasoning and high‑end science, trading blows with Gemini 3 Deep Think. Claude Opus 4.5 trails on ARC‑AGI‑2 but still delivers strong overall performance.
Long‑context
- GPT‑5.2: 400k‑token context window, 128k output, plus
/compactmode (OpenAI API docs, MGX). - Gemini 3 Pro: up to 1M tokens context, still the largest widely accessible context window according to R&D World.
- Claude Sonnet 4.5: long context with strong agent tooling; Anthropic highlights stability over 30‑hour coding sessions (Anthropic).
Interpretation: Gemini 3 Pro still wins on raw context size, but GPT‑5.2 aims at better context quality and retrieval within 400k, and Sonnet 4.5 optimizes around sustained agent workflows rather than pure token count.
4. When GPT‑5.2 Makes Sense (and When It Doesn’t)
Benchmarks only matter if they map cleanly to workloads. Below are realistic scenarios where GPT‑5.2, Gemini 3 Pro, or Claude Sonnet 4.5 are each reasonable first choices.
4.1 GPT‑5.2: Professional Knowledge Work and Agentic Pipelines
GPT‑5.2 is particularly strong when:
- You need spreadsheets, presentations, and reports generated or refactored from messy inputs. GDPval and enterprise case studies in VentureBeat and Fortune suggest that GPT‑5.2 now beats human experts on a broad slice of these tasks.
- Your product relies on long‑running agents that call multiple tools—for example:
- Handling full customer‑service flows (booking, refunds, special accommodations).
- Running internal workflows that combine CRM, billing, and support tools.
- You want strong but not brittle reasoning around new scientific or technical topics, where models like GPT‑5.2 Pro and Gemini 3 Deep Think currently set the pace (R&D World).
GPT‑5.2 is **not **the obvious choice if:
- Your main constraint is lowest possible cost per token for simple classification or FAQ, where smaller models are more economical.
- You require 1M‑token contexts for a single request—Gemini 3 Pro still has a structural advantage there.
- You rely heavily on full‑stack autonomous coding agents over huge repositories; here you should test GPT‑5.2 Thinking directly against Claude Sonnet 4.5.
4.2 Gemini 3 Pro: Giant Context and Video‑Heavy Multimodality
Gemini 3 Pro remains a strong candidate when:
- You truly need 1M‑token windows—for example, simultaneous analysis of very large codebases or document corpora without retrieval.
- Your workflows rely on video understanding or complex multimodal streams where Google has invested heavily and maintains clear strengths (WIRED’s Gemini coverage).
- You already sit deeply in the Google Cloud ecosystem and want consistent integration.
Trade‑offs:
- GDPval and ARC‑AGI‑2 suggest GPT‑5.2 Thinking/Pro now lead on abstract reasoning and structured knowledge work (R&D World.
- For raw coding benchmarks like SWE‑bench Verified, Gemini 3 Pro is strong but now slightly edged out by Claude Sonnet 4.5 (Caylent).
4.3 Claude Sonnet 4.5: Long‑Horizon Coding and Computer Use
Anthropic’s Sonnet 4.5 is explicitly marketed as a coding‑ and agent‑first model, and the numbers support that positioning:
- 77.2% on SWE‑bench Verified, currently the strongest published score in that benchmark class (Anthropic, Caylent).
- 61.4% on OSWorld, the top published score for real‑world computer use—controlling browsers, navigating GUIs, filling forms (Anthropic).
- Demonstrated capacity to run for 30+ hours on complex tasks while maintaining coherence over large codebases (InfoQ).
Sonnet 4.5 is a strong first choice when:
- You are building coding agents (e.g., CI bots, repo refactoring assistants, long‑running dev copilots).
- You need AI to control existing desktop/web tools rather than only calling APIs.
- You want a relatively aligned model for sensitive domains, backed by a detailed system card and ASL‑3 safety level (Anthropic’s system card).
You still should compare it directly with GPT‑5.2 Thinking if your tasks blend:
- Complex coding,
- Heavy document analysis,
- And tool‑oriented workflows.
5. Pricing and Economics
Pricing shifts fast; always check the latest docs. At the time of writing, based on OpenAI’s model page, Anthropic’s announcement, and public coverage:

GPT‑5.2 (API)
- GPT‑5.2 Instant / Thinking:
- $1.75 per 1M input tokens
- $14 per 1M output tokens
- ~90% discount on cached input tokens
- GPT‑5.2 Pro:
- $21 per 1M input tokens
- $168 per 1M output tokens
OpenAI justifies these higher rates by pointing to token efficiency—fewer turns and less retrying for the same tasks (VentureBeat, Fortune).
Claude Sonnet 4.5
- Same base price as Sonnet 4, roughly:
For coding‑heavy workloads, Sonnet 4.5 often offers a strong price‑to‑performance ratio—benchmarks comparable to the most expensive models at a mid‑tier price.
Gemini 3 Pro
- Detailed pricing is available in Google’s model docs and cloud pricing tables; benchmark‑focused summaries can be found in R&D World.
The economic takeaway:
- If your workload is few but high‑value decisions (e.g., legal analysis, major financial decisions), GPT‑5.2 Pro’s cost can be justified by accuracy.
- For continuous coding and agent execution, Claude Sonnet 4.5 is cost‑effective, especially given its SWE‑bench and OSWorld numbers.
- For massive multimodal corpora and 1M‑token contexts, Gemini 3 Pro’s pricing must be weighed against that unique capability.
6. How to Evaluate GPT‑5.2 in Your Own Stack
Reading benchmarks is the easy part. The harder—but necessary—step is measuring how GPT‑5.2 behaves on your actual workload, not on academic test sets.
A practical evaluation loop:
- Define concrete tasks that represent real value.
- “Given a 100‑page compliance manual, draft internal guidelines for a specific team.”
- “Refactor this 50k‑line service to use a new auth library, preserve tests.”
- “Read these three years of quarterly reports and explain key drivers of margin changes.”
- Create a small, labeled test set.
- 20–50 well‑understood tasks where a human “gold answer” or grading rubric exists.
- Include cases involving tool calls, not just plain text.
- Run head‑to‑head comparisons.
- Evaluate GPT‑5.2 Thinking vs at least one competitor (Gemini 3 Pro or Claude Sonnet 4.5) using the same prompts, tools, and time budget.
- Randomize order and blind human graders where possible.
- Measure more than correctness.
- Number of tool calls / steps.
- Tokens consumed and total cost.
- Frequency of explicit “I don’t know” vs confident errors.
- Time‑to‑completion for multi‑turn agents.
- Iterate prompts and routing.
- GPT‑5.2’s Responses API with reasoning tokens, caching, and /compact is a key lever.
- For coding agents, test both plain GPT‑5.2 Thinking and any “Codex‑style” variants OpenAI exposes. If you do not want to hand‑roll this infrastructure, you can run structured experiments through orchestration layers. MGX, for example, is a multi‑agent system built by the MetaGPT team that automates deep research, PRD generation, full‑stack development workflows via chat. It is designed to string together long‑running agents across research, product, engineering, and can serve as a practical environment to compare GPT‑5.2 against other top models on real business tasks. You can try and get more at MGX.dev.
7. Where GPT‑5.2 Fits in the Frontier Model Landscape
Putting everything together:
- If you are an enterprise looking to automate knowledge work—drafting, analysis, reporting, and “agent with tools” workflows across many departments—GPT‑5.2 Thinking is a strong default. GDPval and ARC‑AGI‑2 back this up, and the Responses API plus reasoning tokens offer an actual path to stable long‑running agents.
- If you are primarily building coding agents and dev tools, especially on top of large monorepos, you should treat Claude Sonnet 4.5 as a first‑class candidate alongside GPT‑5.2, given its SWE‑bench Verified and OSWorld performance and its 30‑hour long‑horizon behavior.
- If your workloads demand huge contexts or heavy video understanding, Gemini 3 Pro remains hard to ignore, despite GPT‑5.2’s recent gains on abstract reasoning and professional benchmarks.
Realistically, no single model is dominant across all axes. The rational play for 2025–2026 is multi‑model orchestration, rigorous evaluation, and careful routing based on task type—and that is exactly where platforms like MGX can give you leverage, by wiring frontier models into a coherent multi‑agent “business team” instead of a single monolithic chatbot.
Contents
1. What GPT‑5.2 Actually Is
2. Key Technical Changes in GPT‑5.2
3. Benchmarks: GPT‑5.2 vs Gemini 3 Pro vs Claude Sonnet 4.5 / Opus 4.5
4. When GPT‑5.2 Makes Sense (and When It Doesn’t)
5. Pricing and Economics
6. How to Evaluate GPT‑5.2 in Your Own Stack
7. Where GPT‑5.2 Fits in the Frontier Model Landscape