. Introduction DeepSeek‑V3.2 is the first DeepSeek model designed explicitly around reasoning with tools and agents, rather than treating tool use as an afterthought. Unlike earlier releases that focused mainly on raw language or reasoning performance, V3.2 is built to operate as the core of practical agents: models that must read, think, call tools, and maintain state across many steps.
All factual statements about the model are grounded in public primary sources:
- The official release note for V3.2 and V3.2‑Speciale in the DeepSeek API docs (DeepSeek V3.2 release news).
- The peer‑review‑style technical report DeepSeek‑V3.2: Pushing the Frontier of Open Large Language Models (arXiv:2512.02556).
- The model cards on Hugging Face for V3.2 and related variants (DeepSeek‑V3.2, DeepSeek‑V3.2‑Exp, DeepSeek‑V3.2‑Speciale).
We will also discuss how DeepSeek‑V3.2 performs in real-world use within MetaGPT X. This multi-agent development framework orchestrates role-based agents (product, architecture, engineering, analysis) to build complete applications from natural-language briefs.
2. What DeepSeek‑V3.2 Actually Is
DeepSeek‑V3.2 is a Mixture‑of‑Experts transformer that continues directly from the DeepSeek‑V3.1‑Terminus line. Architecturally, it shares the same overall design as DeepSeek‑V3.2‑Exp; the main change from V3.1‑Terminus is the introduction of DeepSeek Sparse Attention (DSA) during continued pre‑training (arXiv:2512.02556, §2).
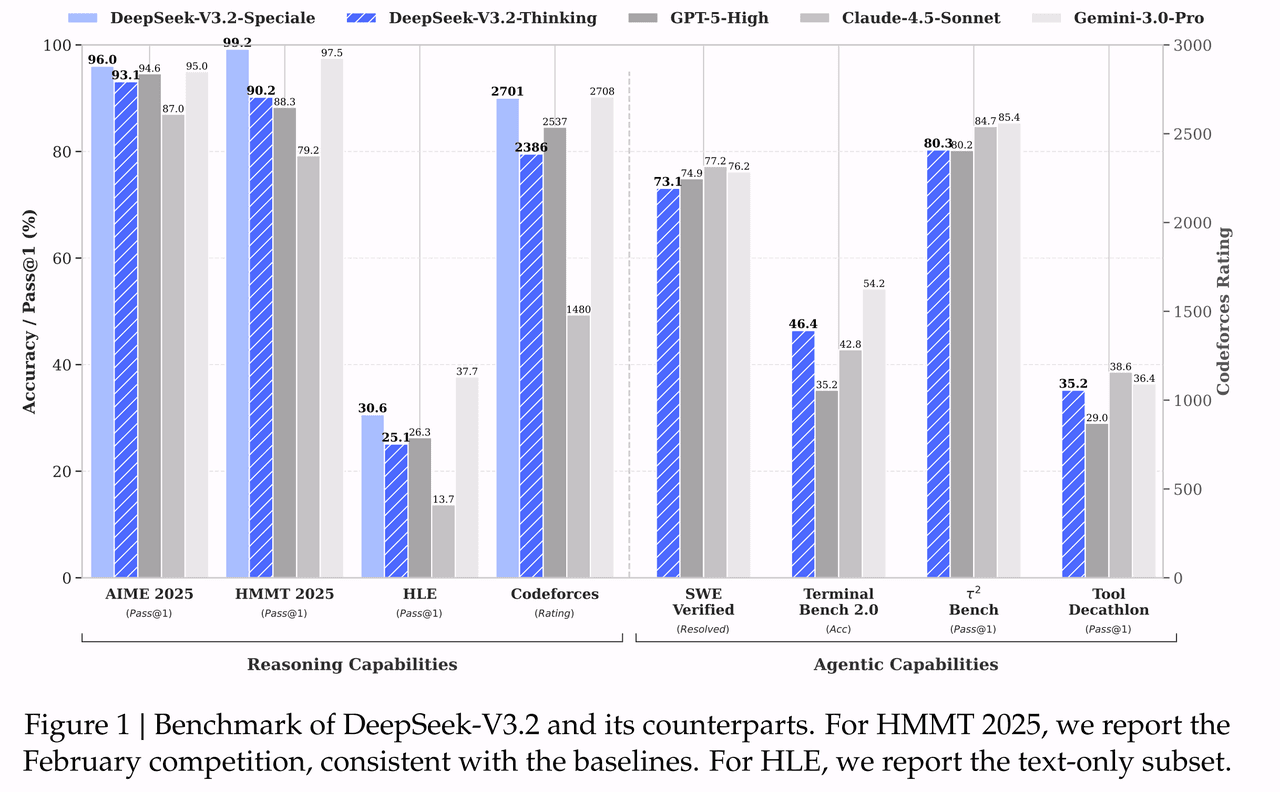 From the Hugging Face model cards, we know:
From the Hugging Face model cards, we know:
- The V3.2 family (V3.2‑Exp, V3.2, V3.2‑Speciale) is a 685B‑parameter MoE model (DeepSeek‑V3.2‑Exp on Hugging Face, “Model size: 685B params”).
- Context length is 128K tokens, inherited from V3.1‑Terminus and extended through long‑context training (arXiv:2512.02556, §2.1.1).
The continued pre‑training that turns V3.1‑Terminus into V3.2 happens in two stages:
- A dense warm‑up stage that trains the new “lightning indexer” component for DSA, with about 2.1B tokens.
- A sparse training stage where DSA is fully activated and the full model is tuned on approximately 943.7B tokens at 128K context length (arXiv:2512.02556, §2.1.1).
The result is a checkpoint that, according to the parity evaluations in the technical report, matches or slightly exceeds V3.1‑Terminus on a broad set of reasoning, coding, and agentic benchmarks, while being substantially more efficient on long contexts (DeepSeek‑V3.2‑Exp model card, arXiv:2512.02556, §2.2–2.3).
On top of this base, the final DeepSeek‑V3.2 model and its high‑compute sibling DeepSeek‑V3.2‑Speciale are obtained through an extensive post‑training and reinforcement learning (RL) process:
- A specialist distillation stage, where reasoning skills from a long‑thinking teacher (DeepSeek‑R1‑type models) are distilled into the base (arXiv:2512.02556, §3).
- A mixed RL procedure built around a scaled‑up Group Relative Policy Optimization (GRPO) variant, with post‑training compute exceeding 10% of pre‑training cost (arXiv:2512.02556, §3.1).
- A large‑scale agentic task synthesis pipeline that creates over 1,800 environments and 85,000 complex prompts to train the model to reason while calling tools (arXiv:2512.02556, §3.2.3).
The official release note confirms that DeepSeek‑V3.2 is deployed as a general‑purpose API model for chat and tool‑based agents, while DeepSeek‑V3.2‑Speciale is offered as a specialised reasoning model with relaxed output length limits (DeepSeek V3.2 API news).
A key point: DeepSeek itself claims that V3.2 “performs comparably to GPT‑5,” and that the Speciale variant “surpasses GPT‑5 and exhibits reasoning proficiency on par with Gemini‑3.0‑Pro” (arXiv:2512.02556, Abstract, DeepSeek‑V3.2‑Speciale model card). Those are vendor claims, not independent measurements. However, they do indicate the performance targets DeepSeek optimised for and frame how the company positions this model within the broader ecosystem.
3. Key Architectural Features: DSA, MLA, and Long‑Context Efficiency
The central technical contribution of DeepSeek‑V3.2 is DeepSeek Sparse Attention (DSA). DSA is not a generic sparse attention mechanism; it is specifically designed to work under Multi‑head Latent Attention (MLA), the attention variant introduced in earlier DeepSeek work (DeepSeek‑V3 technical report).
The basic idea of DSA is:
- Use a “lightning indexer” to assign a scalar score to each pair of query and past token.
- For each query token, retain only the top‑k key–value entries according to these scores.
- Run attention over only that subset rather than over all previous tokens.
Two practical consequences matter for real deployments:
- Complexity reduction: the main attention complexity drops from O(L2)O(L^2)O(L2) to O(Lk)O(Lk)O(Lk) in sequence length LLL and sparsity k≪ L, while the indexer remains lightweight enough to be negligible in overall cost (arXiv:2512.02556, §2.3).
- Preservation of long‑context quality: long‑context benchmarks such as AA‑LCR and Fiction.liveBench show that V3.2 (and its V3.2‑Exp base) match or outperform V3.1‑Terminus in reasoning mode despite the reduced computation (DeepSeek‑V3.2‑Exp model card).
For multi‑agent frameworks like MetaGPT X, long‑context efficiency is not a theoretical concern. Different agents append requirements, design drafts, logs, code, and tool outputs into a shared history. A naïve dense attention model will either run slowly or force aggressive truncation. DSA’s behaviour under MLA is one of the main reasons DeepSeek‑V3.2 can serve as a practical backbone for MGX without prohibitive infrastructure cost.
4. Agentic Training: Thinking with Tools
DeepSeek‑V3.2 is also the first DeepSeek model that “integrates thinking directly into tool‑use” and supports **both thinking and non‑thinking modes in its API **(DeepSeek V3.2 API news, DeepSeek‑V3.2 Hugging Face collection).
The technical report and model cards describe three linked components:
- Specialist distillation from a long‑thinking teacher: DeepSeek‑R1‑style models emit extended chains‑of‑thought. V3.2 uses RL and distillation to keep the reasoning quality while constraining style and length, so that the model remains usable in production chat and tool scenarios (arXiv:2512.02556, §3).
- Scaled RL on real and synthetic agent tasks: Using their GRPO‑based RL setup, the authors allocate a post‑training budget greater than 10% of pretraining compute. This is unusually high in the open‑source space and is targeted at closing the gap on hard reasoning and agentic tasks (arXiv:2512.02556, §3.1).
- Large‑scale agentic task synthesis: To train V3.2 to use tools while “thinking,” DeepSeek constructs more than 1,800 environments and 85,000 complex prompts covering search, coding, code‑interpreter, and general agents. These synthetic trajectories form the backbone of the RL signal for tool‑use generalisation (arXiv:2512.02556, §3.2.3).
On the user‑facing side, this design surfaces as:
- A “thinking” mode (often exposed as a “reasoner” API) where internal reasoning tokens are produced and, optionally, hidden from the end‑user while still guiding tool calls.
- A standard chat mode where the model outputs short, direct answers without visible long chains‑of‑thought.
MetaGPT X can exploit this split by:
- Assigning “thinking” mode to roles that perform deep decomposition and long‑horizon planning, such as architecture and data‑analysis agents.
- Using chat mode for user‑facing roles, such as a client‑facing product manager agent that must stay concise.
Because the thinking mode and tool calls share a single trajectory format (DeepSeek‑V3.2‑Speciale model card), MGX can keep reasoning and actions aligned without juggling multiple models or chat templates.
5. How MetaGPT X Uses DeepSeek‑V3.2
MetaGPT X (MGX) implements a small virtual software team: typical roles include a team lead, product manager, architect, engineer, and analyst. Each role runs on top of the same underlying LLM but is governed by different prompts and SOPs.
With DeepSeek‑V3.2 plugged in as the core model, the workflow for building an application looks roughly like this:
- The user supplies a plain‑language brief (“Build a curated art marketplace,” “Build a bookstore + café website that emphasises memory and place,” etc.).
- The product agent converts this into structured requirements, including user journeys, content structure, and clear non‑goals.
- The architect agent proposes information architecture, page layouts, and high‑level component or API designs.
- The engineer agent writes code for front‑end pages and, if requested, basic back‑end logic.
- The team lead agent monitors progress, resolves role conflicts, and prompts for refinements.
- Optionally, a data agent defines minimal analytics events or reporting needs.
In these experiments, all of these roles are powered by DeepSeek‑V3.2. The MGX analysis of V3.2 itself—also generated by an MGX agent workflow—describes this integration in more detail and cross‑checks it against the official DeepSeek report (MGX DeepSeek‑V3.2 insight).
This setup lets us see DeepSeek‑V3.2 in a realistic environment:
- It must maintain role‑conditioned behaviour: the engineer should not sound like marketing, the architect should not emit final‑user copy.
- It must manage long shared contexts produced by multiple agents.
- It must keep internal consistency between requirements, architecture, and implementation.
The next sections examine two concrete MGX projects built with DeepSeek‑V3.2.
5.1 Case Study 1 – ArtScrap: Curated Art Marketplace
ArtScrap is an MGX‑generated application concept positioned as “a curated artistic marketplace.” The home page built by MGX’s DeepSeek‑V3.2‑powered agents includes:
- A clear hero section with a descriptive tagline and two calls to action (“Explore Gallery” and “Our Story”).
- A Featured Artists section that introduces several fictional artists (e.g., abstract painter, landscape artist, digital artist), each with their primary medium and number of works.
- A Curated Collection grid with individual artworks, including title, artist, medium, size, price, and thematic tags (such as “abstract,” “serene,” “digital”).
- Lightweight trust signals such as counts of artists, artworks, customer satisfaction, and countries covered.
- A closing call‑to‑action and newsletter subscription block. From a model‑evaluation perspective, several properties stand out.
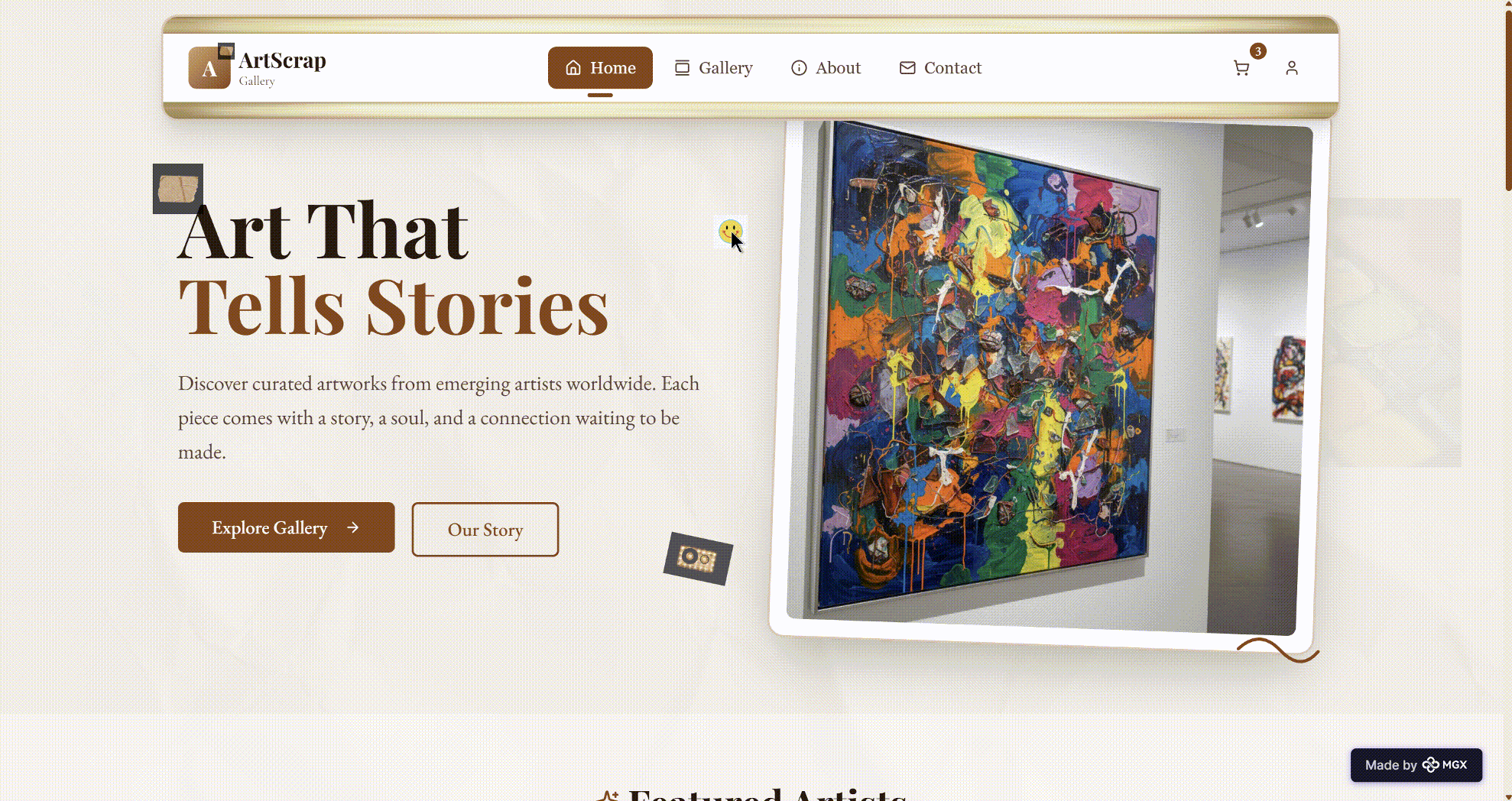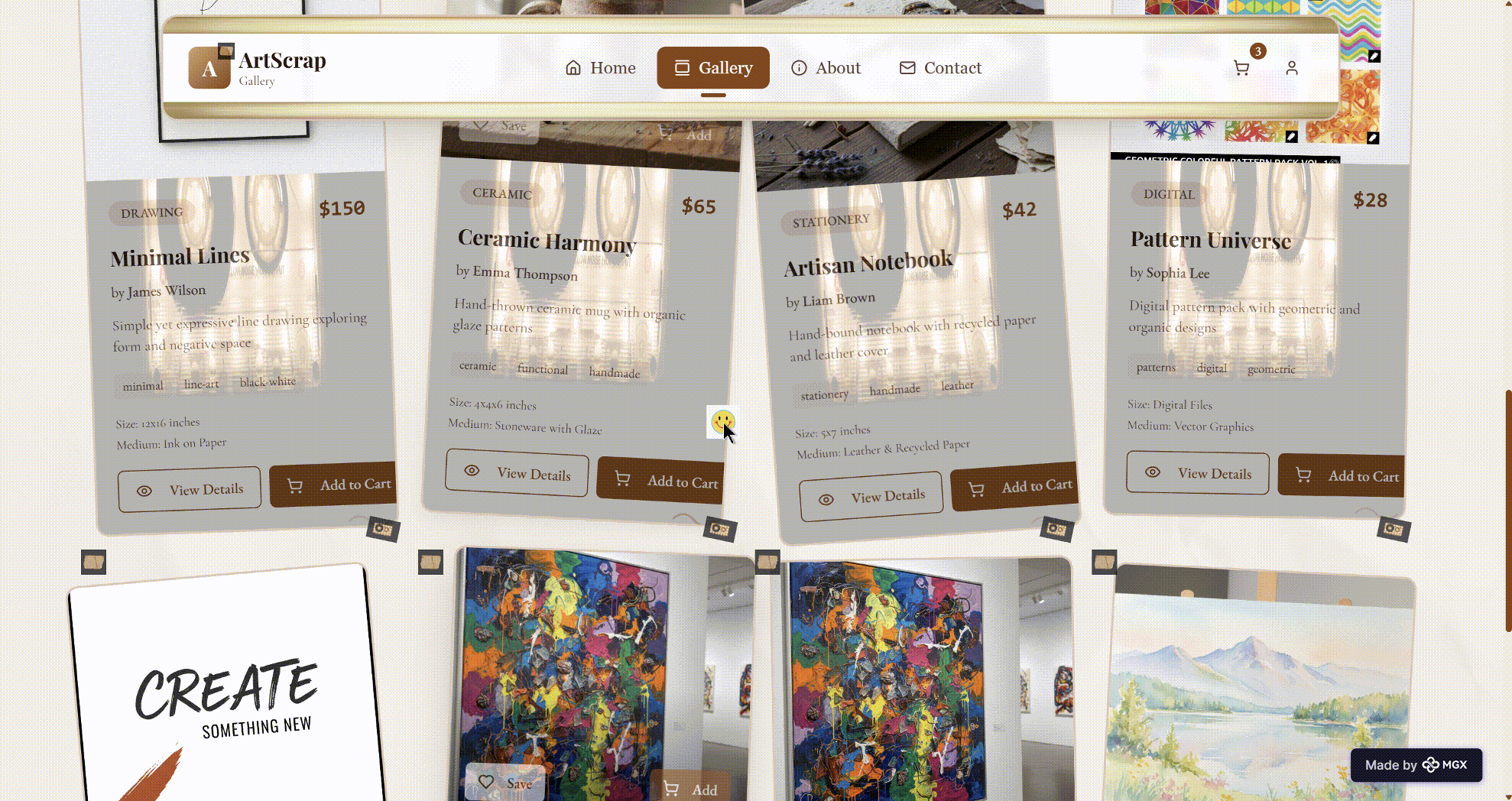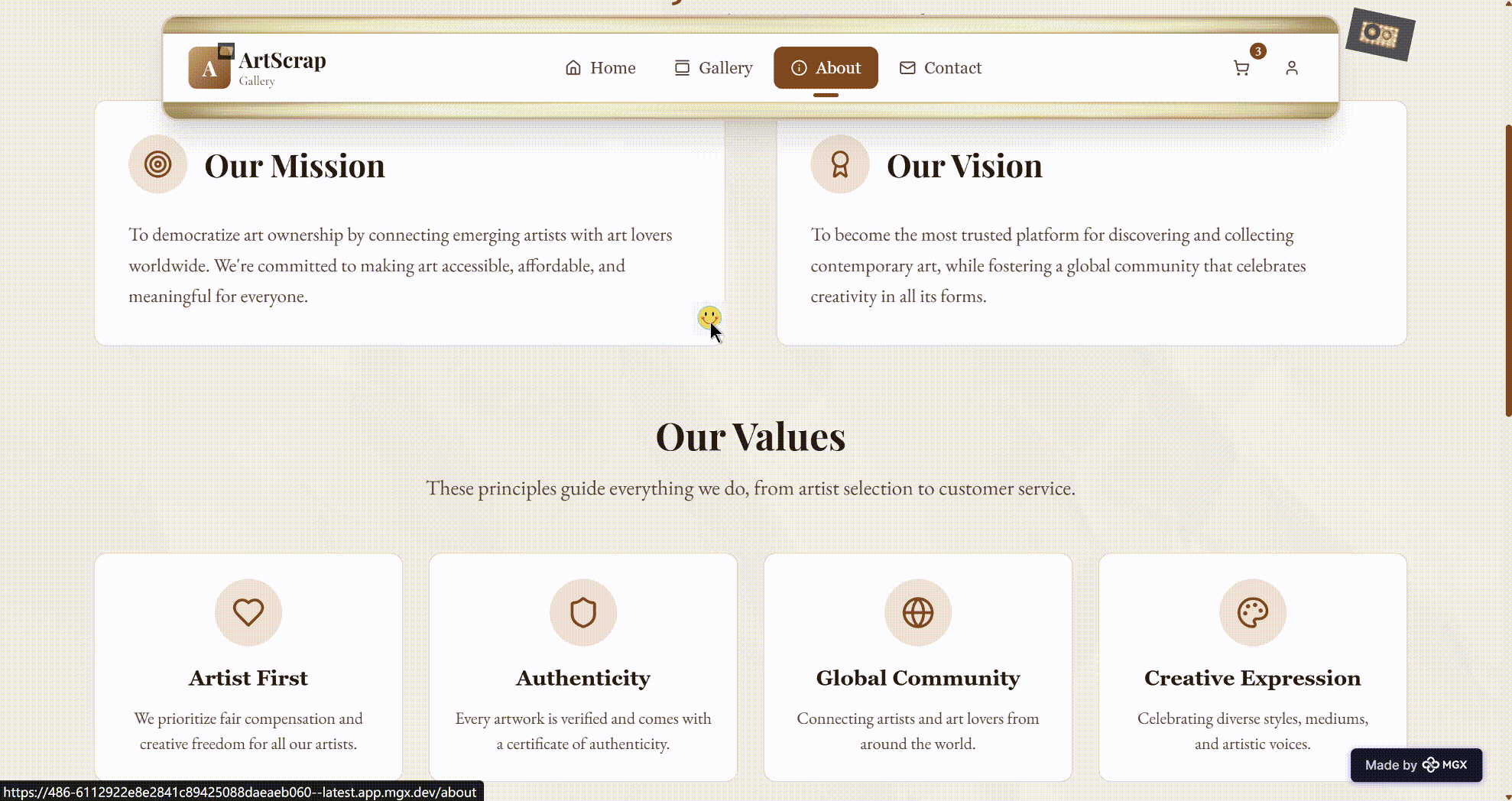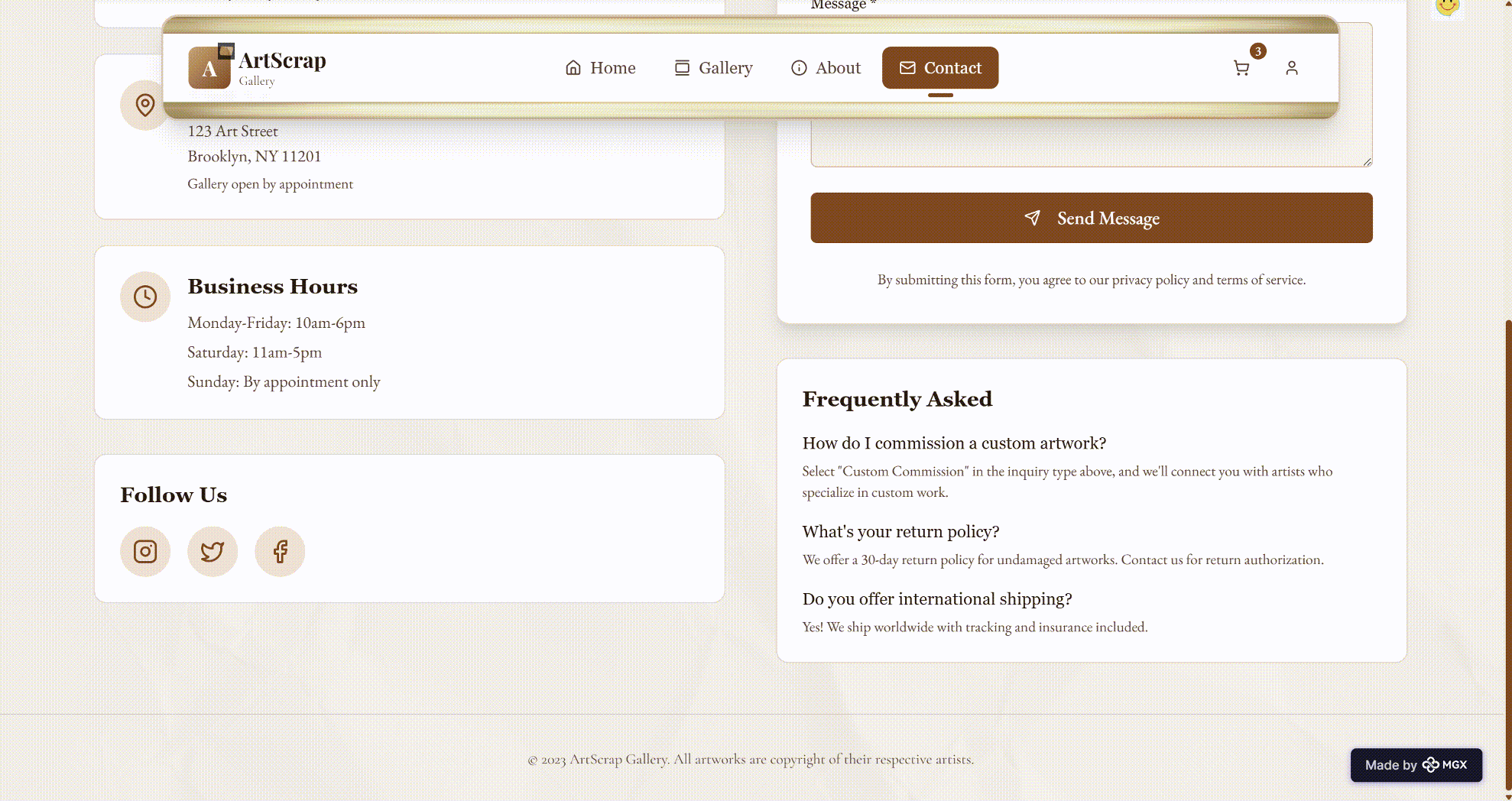
First, the information architecture is coherent and follows established marketplace patterns without directly copying any well‑known site. DeepSeek‑V3.2 in the architect role produces a top‑level structure that makes sense for first‑time visitors: understand the brand → meet the artists → browse selected works → gain trust → act. This is aligned with basic UX best practices, not just generic content generation.
Second, the semantic consistency between copy and metadata is solid. When a product is labelled “Mixed media painting exploring color and texture,” its tags and medium are aligned (“mixed‑media,” “acrylic & oil on canvas”). This matters in MGX because content and metadata are often produced in separate steps by different agents; DeepSeek‑V3.2 keeps them synchronised over a shared context.
Third, the tone and length of content are controlled. Product descriptions are short and focus on relevant attributes rather than inflated claims. Artist bios introduce style and focus without drifting into irrelevant details. This suggests that, once the product agent defines a “voice” for the platform, DeepSeek‑V3.2 can keep it stable across multiple sections.
5.2 Case Study 2 – Chapter & Verse: Independent Bookstore & Café
The Chapter & Verse project targets a different axis: a combined bookstore and café that emphasises atmosphere, theme, and sense of place. The generated site includes:
- A hero section introducing the venue as “a tranquil space where literature meets leisure” with CTAs to browse books and view the menu.
- A “The Space” section split into sub‑areas: a reading nook, café counter, curated collections, and a seasonal menu, each with a short description accompanied by a relevant image slot.
- A Featured Collection of books tied to a common theme (“memory, place, and the passage of time”), each with an author line and a one‑sentence commentary.
- A Plan Your Visit section detailing address, opening hours, contact details, and a literary quote.

Here, DeepSeek‑V3.2’s behaviour differs from ArtScrap in meaningful ways.
The narrative structure is more pronounced. Instead of jumping immediately into “products,” the page invites the user to imagine the physical space, then introduces themed reading, and only then moves to practical information. This reflects a product brief where experience and identity are more important than conversion. The model respects that priority ordering without being explicitly told to “tell a story first” in every section.
The book annotations show controlled knowledge use. Titles and authors such as The Memory Palace or A Field Guide to Getting Lost are grounded in real works known in the broader literary and essay tradition. The one‑sentence descriptions connect them correctly to themes of memory, wandering, and time, without fabricating implausible details. This is a small but useful check on factual behaviour in a low‑risk domain.
The tone is consistent with independent bookstores rather than large retailers. Phrases focus on “quiet corners,” “carefully designed environment,” and “thoughtfully organised shelves by mood and theme.” For an MGX workflow, this indicates that DeepSeek‑V3.2 can reliably maintain brand voice guidelines provided up front, even as different roles collaborate on space descriptions, collection notes, and practical information.
5.3 Case Study 3: Acid Graphics – Y2K Cyberpunk Fashion Storefront
The third application generated by MetaGPT X with DeepSeek‑V3.2 is ACID GRAPHICS, a single‑brand e‑commerce storefront for Y2K‑style, cyberpunk fashion and tech accessories.
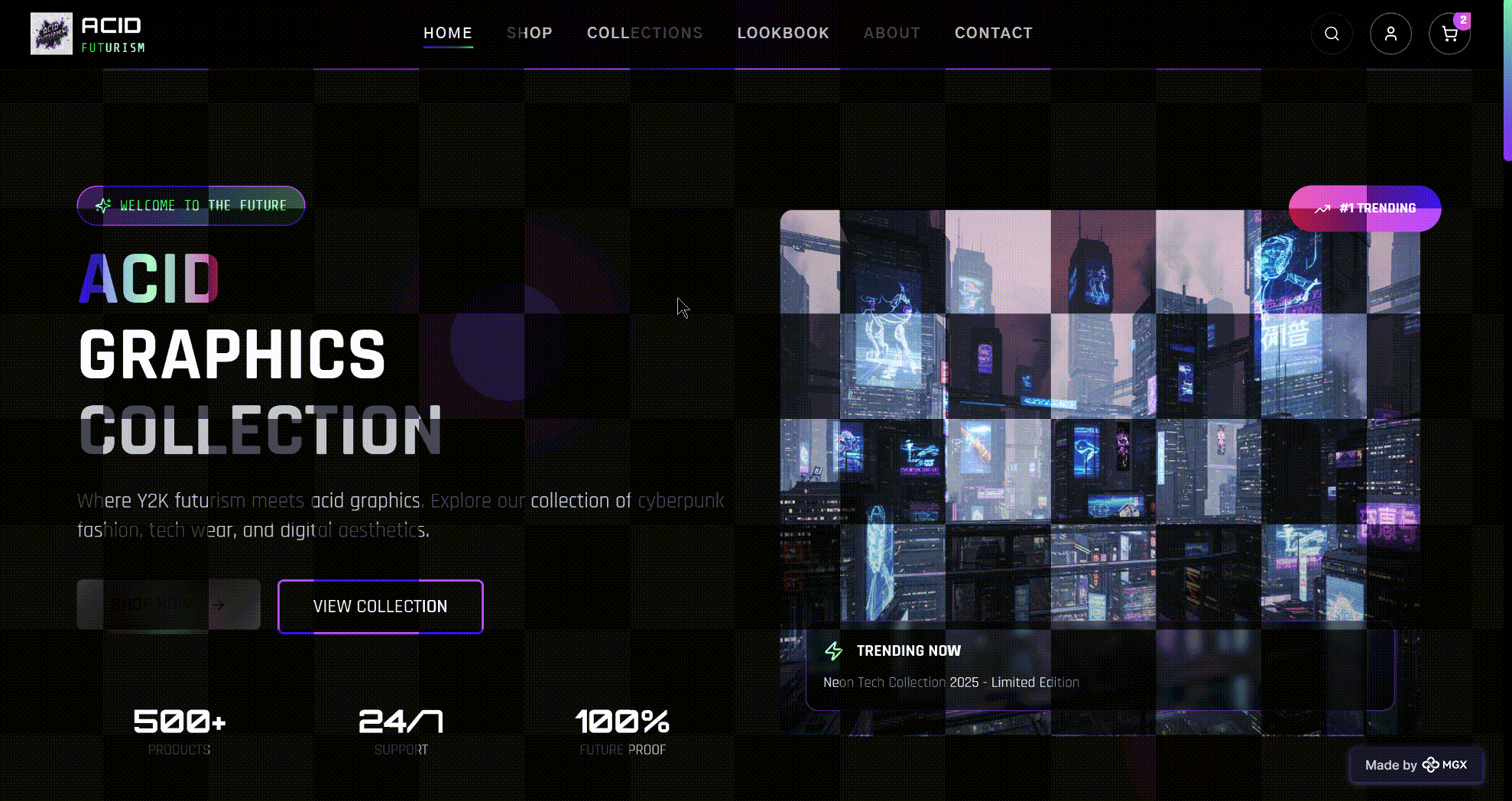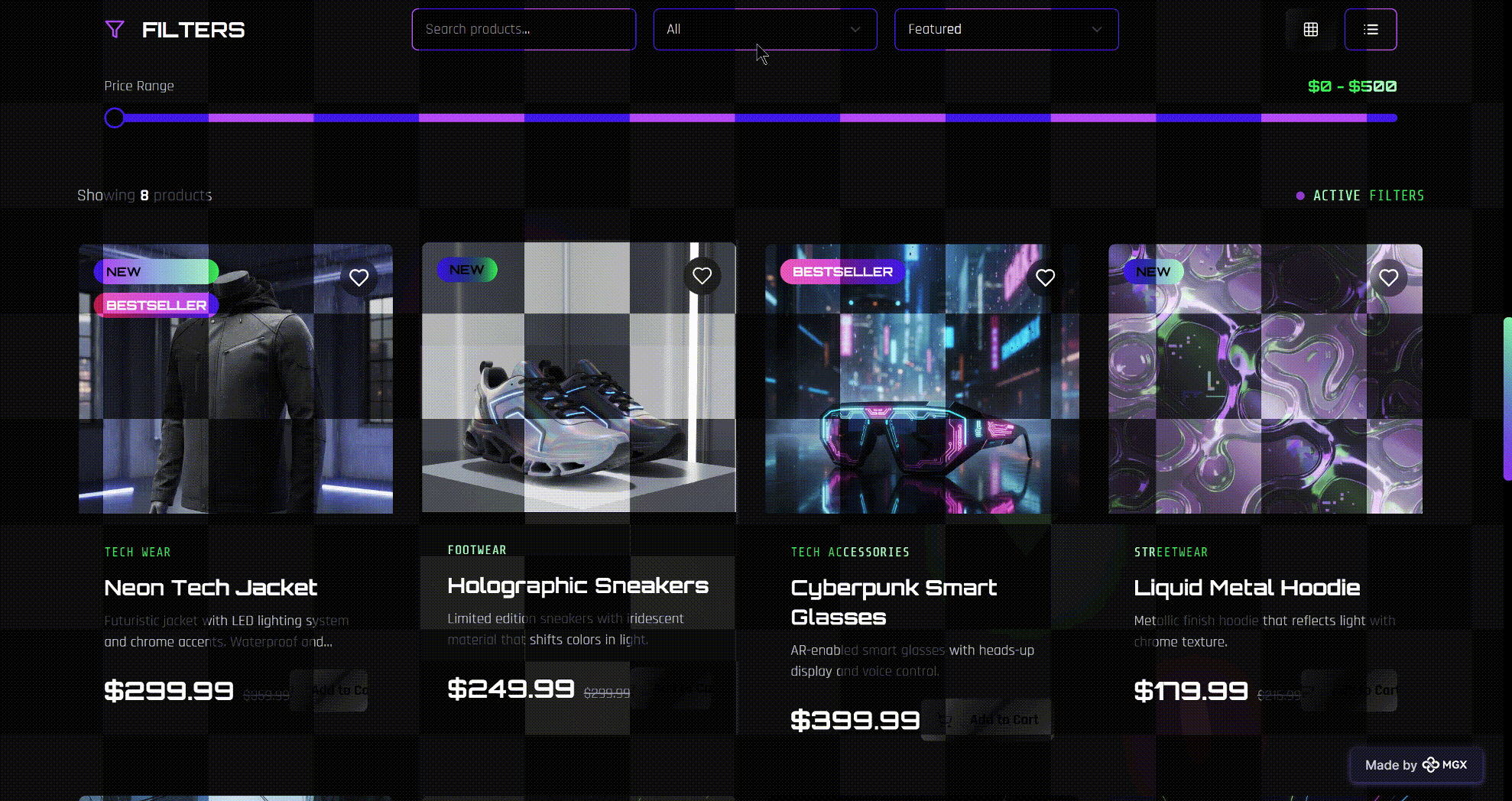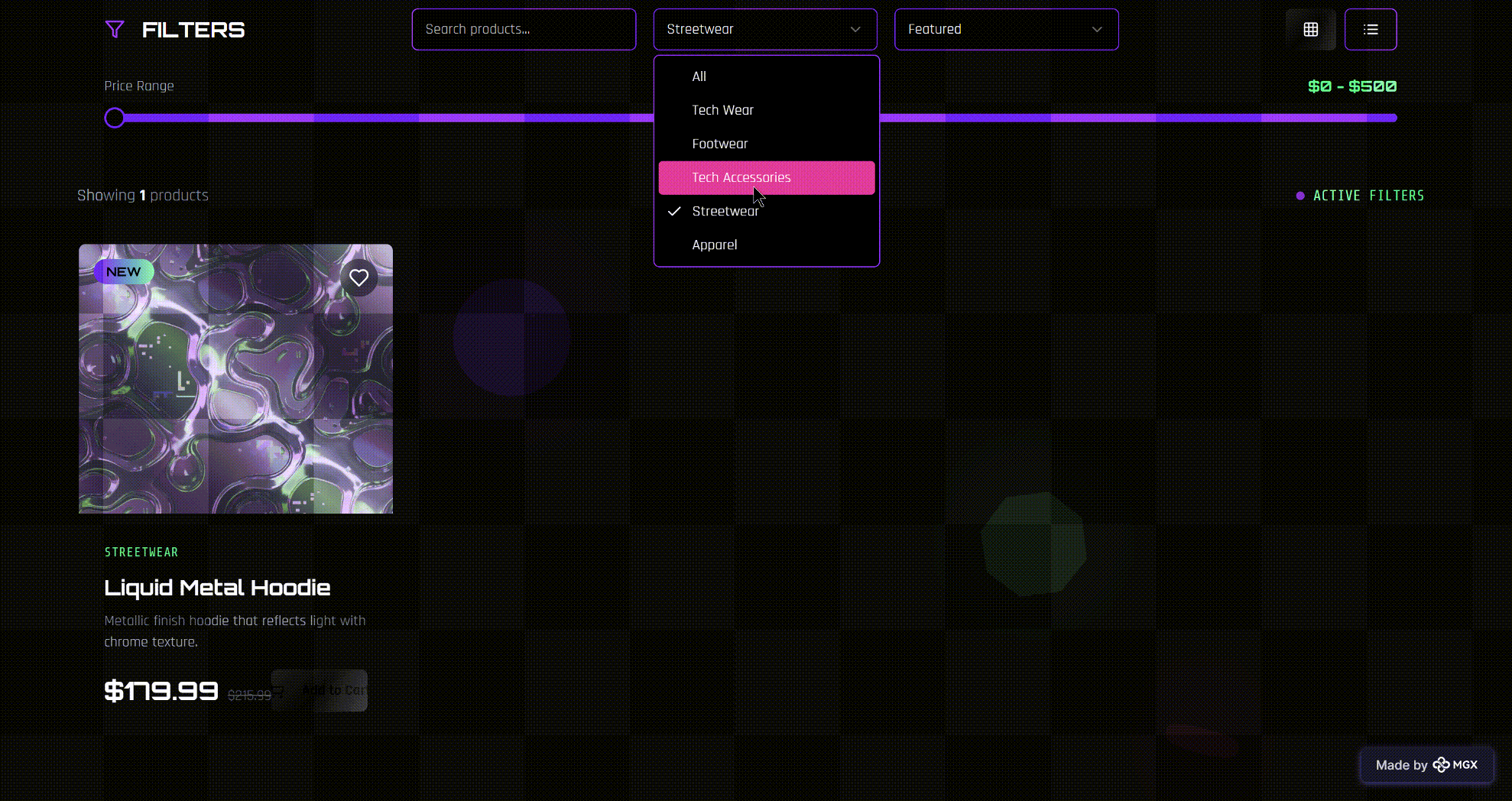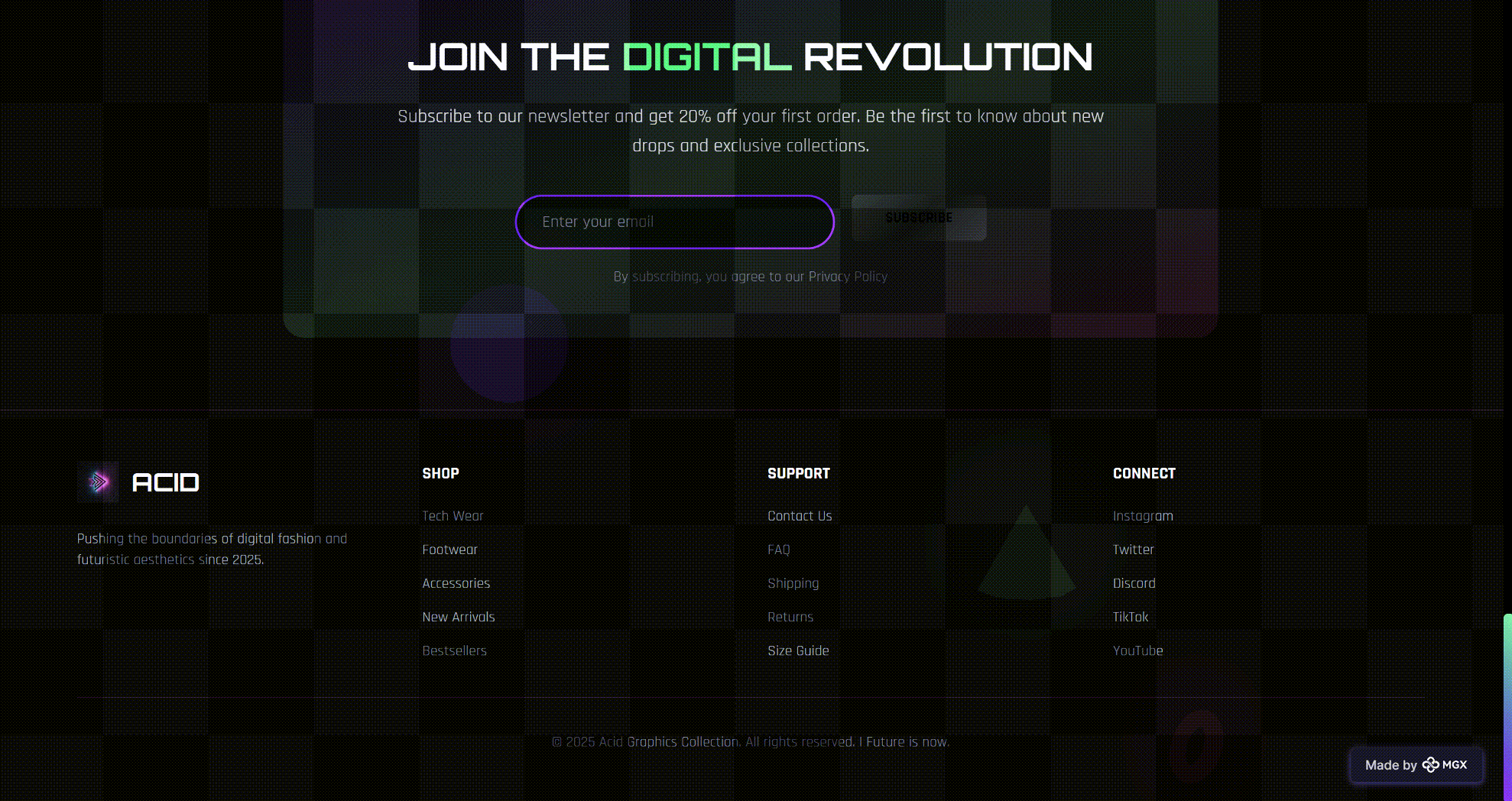
Unlike ArtScrap and Chapter & Verse, which emphasize narrative and curation, ACID GRAPHICS is built around high‑density product display and aggressive visual branding. The site opens with a full‑bleed “WELCOME TO THE FUTURE / ACID GRAPHICS COLLECTION” hero, a futuristic city background image, and three simple proof‑points:
- “500+ PRODUCTS”
- “24/7 SUPPORT”
- “100% FUTURE PROOF”
6. Strengths, Limitations, and Practical Recommendations
Pulling together the official documentation and MGX experiments, a pragmatic view of DeepSeek‑V3.2 looks like this:
- Architecturally, it is a 685B‑parameter MoE transformer with DSA‑based sparse attention for long contexts and a 128K window (DeepSeek‑V3.2‑Exp, arXiv:2512.02556, §2).
- It has undergone large‑scale RL and agentic post‑training with more than 1,800 synthetic environments and 85,000 complex prompts for tool‑using agents (arXiv:2512.02556, §3.2.3).
- The authors report parity or near‑parity with leading proprietary models on several reasoning and agentic benchmarks, and gold‑medal performance for the Speciale variant on contests such as IMO and IOI 2025 (arXiv:2512.02556, Abstract, DeepSeek‑V3.2‑Speciale).
In the MGX setting, the strengths that matter most are:
- Reliable coding and structural reasoning for small to medium‑sized applications.
- Stable role‑conditioned behaviour under strong prompts and SOPs.
- Good long‑context handling in multi‑agent logs due to DSA and MLA.
At the same time, DeepSeek‑V3.2 is not a magic solution:
- The technical report’s limitations section (and standard experience with current LLMs) emphasise that hallucinations and tool‑use errors still occur, especially in open‑domain or high‑stakes contexts (arXiv:2512.02556, §5).
- Complex, real‑world deployment still requires human review, monitoring, and guardrails. Neither DeepSeek‑V3.2 nor MGX, as used here, is designed for unsupervised, safety‑critical decisions.
For teams considering DeepSeek‑V3.2 as the core model in an MGX‑style setup, a realistic recommendation is:
- Use V3.2 as a backbone for code, structured content, and multi‑agent planning where human engineers and product owners remain in the loop.
- Consider the V3.2‑Speciale variant for offline reasoning‑intensive tasks (e.g., competition‑style math or algorithm design) where its lack of tool‑calling is acceptable and long‑form thinking is an advantage.
- Combine MGX’s strong SOPs with explicit quality gates: tests for generated code, editorial review for copy, and clear risk boundaries for any tool that can affect real systems. Within that envelope, DeepSeek‑V3.2 delivers a useful combination of capacity, efficiency, and agent‑oriented training that makes it a credible base for multi‑agent software development workflows.
Contents
1. Introduction
2. What DeepSeek‑V3.2 Actually Is
3. Key Architectural Features: DSA, MLA, and Long‑Context Efficiency
4. Agentic Training: Thinking with Tools
5. How MetaGPT X Uses DeepSeek‑V3.2
6. Strengths, Limitations, and Practical Recommendations