
Google did not position Gemini 3 Pro as a small iteration. On November 18, 2025, it introduced Gemini 3 as its “most intelligent model” so far, with Gemini 3 Pro as the first flagship variant. The official announcement focuses on three things: reasoning, multimodality, and what Google calls “agentic” coding and planning (Google product blog).
This piece has two goals:
- Explain what Gemini 3 Pro is, in concrete technical terms, with links back to primary sources.
- Show what it looks like in practice when you pair it with Atoms and ask it to build real, interactive applications end‑to‑end.
No slogans, no hype. Just what the model does, where it’s strong, where it is simply new, and what that means if you care about building with it.
1. What is Gemini 3 Pro?
Gemini 3 Pro is the first model in Google’s Gemini 3 family, exposed to developers under the ID gemini-3-pro-preview (Gemini 3 Developer Guide). Compared to earlier Gemini releases, it combines three properties that normally do not arrive together:
- a 1 million‑token input context window,
- native multimodality across text, code, images, audio, video, and long documents,
- benchmark scores that put it among the top publicly available models on reasoning and coding tasks.
On the API side, Google’s own documentation gives the basic spec (Gemini 3 Developer Guide, Vertex AI model card):
- Input context up to 1,048,576 tokens; output up to 65,536 tokens.
- Knowledge cutoff in January 2025.
- Supported inputs include text, code, up to 900 images, videos up to roughly 45–60 minutes, PDFs and other documents up to 900 pages.
- A default “high thinking” mode, with an explicit thinking_level parameter to trade depth against latency.
- Fine‑grained media_resolution controls to balance vision quality against token cost for images, documents, and video frames.
The model is exposed to end users through the Gemini app and AI Mode in Search, and to developers through the Gemini API, Google AI Studio, Vertex AI, Gemini CLI, and Google’s new Antigravity environment (Google developer blog, Google Cloud blog).
None of this, by itself, proves it is good. The real signal comes from independent evaluations.
2. How strong is it really? Benchmarks and independent analysis
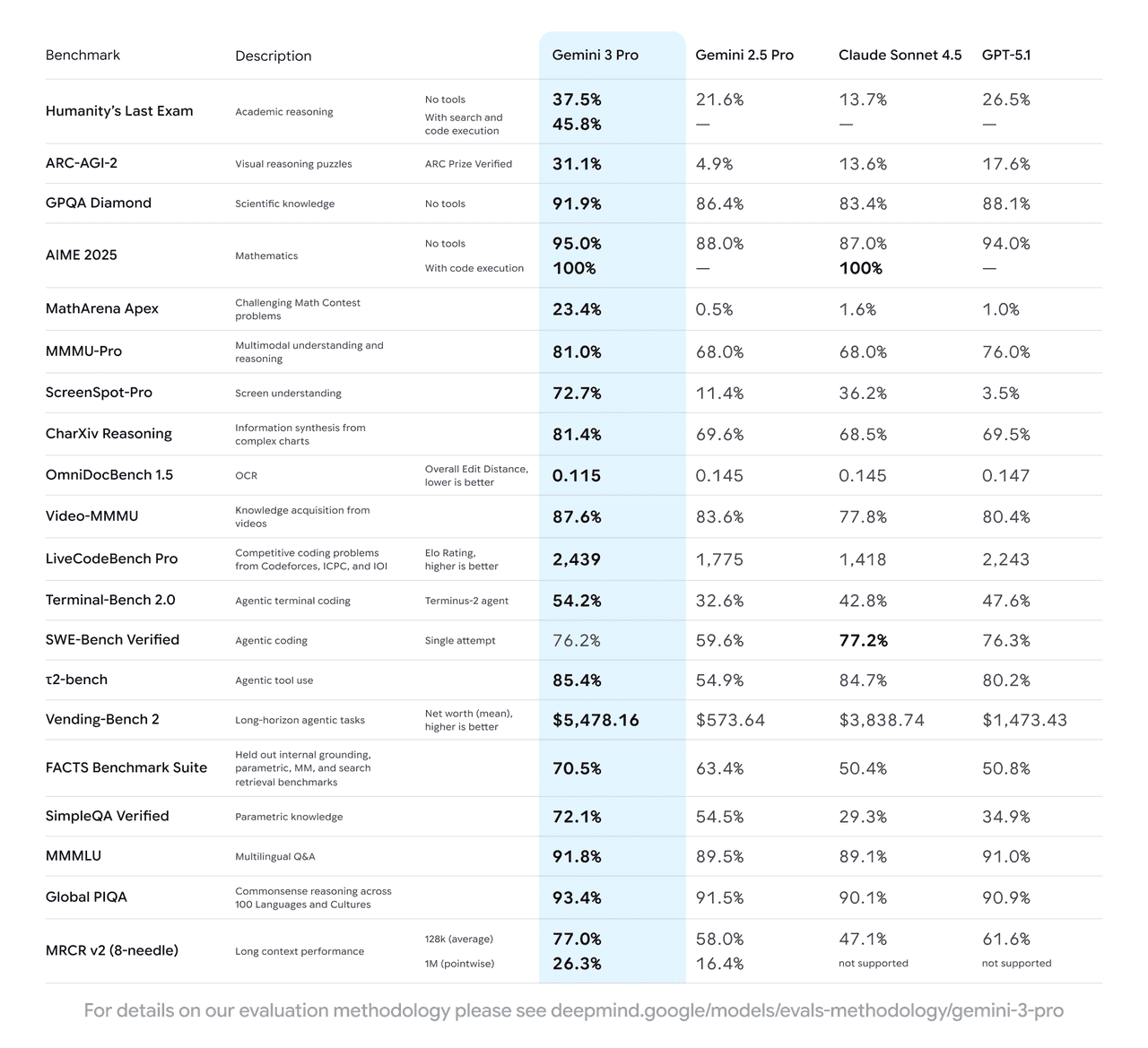
Google’s own benchmark table in the product blog is unambiguous: Gemini 3 Pro outperforms Gemini 2.5 Pro on every major test they report, including academic reasoning, math, multimodal understanding, and coding (Google product blog). That is marketing from the source. To get a more cautious picture, it helps to look at third‑party analysis.
The MGX deep‑dive, which aggregates public benchmarks and vendor data, summarizes it bluntly: Gemini 3 Pro currently sits at or near the top on a long list of reasoning, multimodal, and coding benchmarks when compared to models like GPT‑5.1 and Claude 4.5 (MGX in‑depth analysis of Gemini 3 Pro). A few examples from that report, cross‑checked with the underlying sources it links:
- LMArena ranking: Gemini 3 Pro achieves an Elo of 1501, ahead of Gemini 2.5 Pro (1451) and other leading models (LMArena scores quoted in Google’s blog).
- GPQA Diamond (graduate‑level scientific QA): 91.9%, above prior Gemini models and above most competitors in the same test set (MGX benchmark table).
- MathArena Apex (hard math contest problems): 23.4%, where previous models and peers sit in the low single digits.
- Multimodal: 81.0% on MMMU‑Pro and 87.6% on Video‑MMMU, both strong scores for image‑ and video‑based reasoning tasks.
- Coding and tools: 1487 Elo on WebDev Arena, 76.2% on SWE‑bench Verified, and 54.2% on Terminal‑Bench 2.0 for terminal‑driven coding agents (Google developer blog, MGX analysis).
An independent index by Artificial Analysis, cited in MGX, puts Gemini 3 Pro slightly ahead of GPT‑5.1 on aggregate reasoning and multimodal performance, and notes that it leads their chart on several specific benchmarks, including GPQA Diamond and long‑context MRCR v2 (The Decoder summary).
The other side of the story is cost and reliability. MGX points out that:
- Pricing is USD 2 per million input tokens and 12 per million output tokens under 200k tokens, rising to 4 and 18 above that threshold (Gemini 3 Developer Guide).
- Token efficiency is better than Gemini 2.5 Pro, but overall benchmark runs cost around 12% more due to higher rates (MGX analysis).
- Knowledge tests show around 88% factual accuracy, with a hallucination rate still non‑trivial and, in some tests, higher than select competitors. This is consistent with broader coverage that notes Gemini 3’s strengths in reasoning but warns that it is not immune to fabrication (Android Authority overview).
In short: Gemini 3 Pro is not perfect, but on the numbers it is one of the strongest public models available as of late 2025, especially when tasks require long context, structured reasoning, or multimodal input.
3. What is actually new in how it works?
Under the hood, Gemini 3 Pro is not a simple “bigger transformer”. MGX’s technical section describes it as a sparse Mixture‑of‑Experts transformer architecture, with different experts activated for different inputs, and a training stack tuned for TPU pods (MGX architecture deep‑dive). That is interesting from a research perspective, but day‑to‑day, three surface‑level design choices matter more to builders.
First, the 1M‑token context window is not just a marketing number. The developer guide describes explicit long‑context benchmarks (MRCR v2 at 128k and 1M tokens) where Gemini 3 Pro maintains usable performance even at 1M input tokens (Gemini 3 Developer Guide). Practically, this lets you feed entire codebases, multi‑hour transcripts, or long mixed media without slicing them into artificial chunks. It does not mean every workload should use 1M tokens, but for code understanding, compliance reviews, and large research bundles, it changes what is practical.
Second, multimodality is native rather than bolted on. The model takes images, video frames, and audio features directly, rather than only via separate encoders mapped into text. Tokens per frame or page are controlled by the 'media_resolution' parameter, which lets you cap the per‑image budget for OCR and fine detail versus general understanding. The developer docs are explicit about the recommended settings for images, PDFs, and video (Gemini 3 Developer Guide).
Third, Google exposes reasoning controls. In Gemini 3, internal “thinking” is not just an invisible chain‑of‑thought. There is:
- a
thinking_levelflag (lowvshigh) that directly affects how much internal reasoning the model performs before answering; - a concept of “thought signatures”, which are encrypted traces of reasoning that must be passed back in multi‑turn tool‑calling flows if you want the model to stay coherent across steps.
The guide is clear: omit those signatures, and the model will behave less consistently in complex multi‑step flows. Use the SDKs and appropriate history handling, and you keep the reasoning context intact (Gemini 3 Developer Guide: Thinking and thought signatures). These are not cosmetic parameters. They signal that Gemini 3 Pro is designed to be driven as a long‑running reasoning engine, not just a fancy autocomplete.
4. Gemini 3 Pro on MetaGPT X: from prompt to live app
All of this is still abstract until you see the model build something real. MetaGPT X connects Gemini‑class models to a pipeline that can plan, write, and deploy applications. With Gemini 3 Pro plugged into that stack, a few characteristics become very visible:
- it is much less fragile when you ask for complex UI and physics,
- it holds a long chain of layout and interaction constraints in its head,
- it can stay on brief for an entire experience rather than just a fragment.
Five MetaGPT X cases built on top of Gemini 3 Pro illustrate this.
4.1 Cosmic countdown for the Gemini 3 launch
The first case is a particle‑driven cosmic countdown: rotating nebula clouds, a dynamic particle field, and a final solar‑flare‑style explosion revealing the Gemini 3 Pro release.

4.2 A physics‑based fruit merge game
The second case is a fruit merge puzzle in the spirit of the Watermelon Game:
- Fruits drop from the top when the user clicks or taps.
- Identical fruits merge into larger ones when they collide.
- The game ends when stacked fruits cross a red line.

4.3 A Swiss‑style brutalist portfolio layout
The third case is a minimalist portfolio landing page:
- black‑and‑white palette,
- brutalist typography with oversized type,
- a responsive Bento grid for projects,
- Swiss design cues in spacing and hierarchy.

4.4 A glassmorphism Kanban board
The fourth case is a glassmorphism task board:
- frosted‑glass cards and columns,
- card creation and editing,
- smooth drag‑and‑drop across columns,
- responsive layout with consistent blur and transparency.
Here the constraints are partly visual (glass aesthetic done cleanly) and partly interaction‑centric (drag‑and‑drop that does not fall apart as the board grows). Gemini 3 Pro, given a description of the desired style and behavior, generates:
- CSS that actually produces believable glassmorphism on modern browsers,
- JavaScript or React logic for tracking card state and positions,
- accessible fallbacks that keep the board usable without perfect pointer events.

4.5 A 3D zero‑gravity Playground
The fifth case is an interactive 3D scene described as a “digital magic, zero‑gravity” environment:
- objects float and interact under custom physics,
- the user can manipulate elements and see immediate response,
- the composition stays coherent even as more objects are added.

5. Where Gemini 3 Pro fits in a builder’s toolkit
Stepping back from the individual demos, a few practical observations are worth making.
First, Gemini 3 Pro is clearly overkill for trivial chat or short text. Simpler, cheaper models are better suited to basic support bots or FAQ answers. Where the model earns its cost is when you need either:
- a very long, heterogeneous context window (large codebases, multiple documents, long audio/video),
- non‑trivial planning and tool use (multi‑step workflows, code editing, environment interaction),
- complex multimodal tasks (combined text, diagrams, screen layouts, videos) that need to be understood in one pass.
Google’s own guidance for enterprises highlights exactly these scenarios: analysis of large document sets, multi‑modal diagnostics, and long‑horizon planning tasks like supply chain and forecasting (Google Cloud blog).
Second, pairing Gemini 3 Pro with a system like MetaGPT X changes the practical ceiling on “idea to app” flows. The MGX report describes Gemini 3 Pro as “exceptional at zero‑shot generation” and notes its strength in what Google calls “vibe coding” — building apps from high‑level natural language only (MGX analysis, Google developer blog). On MetaGPT X, this shows up as:
- fewer rewrites when generating full UI + logic;
- more consistent adherence to detailed style and interaction constraints;
- more robust long‑chain editing, where the model can refactor its own output across multiple files.
Third, the model is still a generative system with known weaknesses. It can hallucinate, it can produce code that compiles but does not fully respect edge cases, and it benefits from guardrails. The independent analysis MGX cites is explicit that hallucination rates, while improved in some areas, remain a concern and can be higher than some peers on selected tests (MGX analysis). Any serious use of Gemini 3 Pro, on MetaGPT X or elsewhere, still requires:
- validation against tests or type systems,
- constraints on what the model is allowed to do in a live environment,
- clear boundaries between exploration and production changes.
Finally, cost and latency have to be considered. A 1M‑token context window is powerful, but it is not free. Google’s own pricing and performance notes make it clear that developers are expected to use the context window and multimodal resolution carefully, not indiscriminately (Gemini 3 Developer Guide). MetaGPT X can help here by orchestrating when to ask for full‑context runs and when to keep calls small.
6. Closing
Gemini 3 Pro is not just another model to add to a dropdown. It moves a few things from “almost works but not quite” into “usable” territory:
- full applications generated from a single prompt that do more than render a static page,
- reliable incorporation of design language and layout constraints across an entire UI,
- long‑horizon agent behavior that can work through multi‑step coding and planning tasks.
The external numbers — from Google’s own benchmarks, from independent aggregators, and from analyses like the MGX report — support the claim that this is one of the most capable general‑purpose models currently accessible in production APIs (Google product blog, MGX in‑depth analysis, Artificial Analysis summary).
On MetaGPT X, that capability is visible not in synthetic benchmarks but in concrete outputs: a cosmic countdown that stands up as a launch piece, a small physics game that actually plays well, a Swiss‑style portfolio that respects grid discipline, a glass Kanban board you can drag cards on, and a 3D Playground that behaves like a coherent space rather than a stack of random examples.
There will be more models, and newer ones will eventually surpass Gemini 3 Pro. For now, if you care about building rich interfaces, agent‑like workflows, or long‑context applications, it is a model worth taking seriously — and, as the MetaGPT X cases show, one that already does more than just talk about what it could do.
7. Try Gemini 3 Pro on MetaGPT X
Gemini 3 Pro is currently one of the few models that can realistically take you from “describe it in plain English” to “here is a working, interactive product” — especially once you plug it into an agentic engine like MetaGPT X.
If you want to:
- ship real UI and games instead of toy demos,
- run long‑context analysis over codebases and documents,
- or prototype complex, multi‑step agents without wrestling the model at every turn,
you can start using Gemini 3 Pro directly inside MetaGPT X.
See the full capabilities, benchmarks, and current pricing on the MGX page here: MetaGPT X & Gemini 3 Pro
From there, you can decide whether the performance and cost profile of Gemini 3 Pro on MetaGPT X makes sense for your own stack — and, if it does, go from reading about the model to actually building with it.