
2025 is the first year where “which LLM should I use?” is a real architectural decision, not a default to a single vendor.
Closed‑weight systems like GPT‑5.2, Gemini 3 Pro and Claude 4.5 stretch reasoning, agents and multimodality. Open‑weight families like DeepSeek‑V3.2 and Qwen3 narrow the gap at a fraction of the cost. On top of them, products like NotebookLM show what a fully model‑backed application looks like.
This piece focuses on the models themselves: how they’re built, what’s distinctive technically, and where they actually shine. No hype, no slogans—only capabilities, trade‑offs and concrete numbers where public sources allow.
For deeper prompt‑level comparisons, it’s worth pairing this with analyses like the GPT‑5.2 vs Gemini 3 Pro vs Claude 4.5 Sonnet comparison.
1. The 2025 LLM landscape in one page

1.1 Release timeline and who leads what
If you look at the model‑version timeline kept by LLM‑Stats and the community AI Timeline, you get a clear picture of the last 12 months:
-
Nov 2025: Google ships Gemini 3 Pro and Deep Think, plus the Gemini Agent and Antigravity environment, with very strong scores on ARC‑AGI‑2, AIME 2025 and multimodal benchmarks.
-
Dec 2025: OpenAI responds with GPT‑5.2 (Instant, Thinking, Pro), emphasizing long‑context, “reasoning tokens”, and agent workflows.
-
Sep–Nov 2025: Anthropic rolls out Claude 4.5 Haiku, Sonnet, Opus, with Sonnet and Opus 4.5 aimed squarely at coding and long‑running agents.
-
2025 throughout: Chinese labs push open‑weight systems:
-
DeepSeek‑V3.2 and DeepSeek‑R1 evolve into low‑cost “thinking” and “non‑thinking” variants.
-
Qwen3‑235B‑A22B from Alibaba becomes one of the strongest open MoE models with 235B parameters (22B active).
-
-
Meta and Mistral iterate open‑source lines (Llama 4 family, Ministral 3 / Mistral Large 3), while xAI’s Grok‑4.1 and others compete near the top of reasoning leaderboards.
Different sources disagree on “who is #1 overall”. But if you look across benchmarks like GPQA, MMLU, ARC‑AGI‑2, SWE‑Bench, LiveCodeBench and Screen‑based agent tests, a pattern emerges:
-
GPT‑5.2 Thinking / Pro and Gemini 3 Deep Think tend to top reasoning, coding and long‑horizon tasks.
-
Claude Sonnet 4.5 / Opus 4.5 are extremely strong at agentic tool use and “using computers”, with conservative behavior and detailed step plans.
-
DeepSeek‑V3.2 and Qwen3‑235B are the most capable open‑weight LLMs that can realistically be self‑hosted while staying competitive with the above in many workloads.
That’s the macro view. Now into the individual families.
2. GPT‑5.2: Deep reasoning and long‑context workhorse
OpenAI describes GPT‑5.2 as its strongest series “for professional knowledge work”, with three main variants: Instant, Thinking, and Pro.
2.1 Architecture and modes
From OpenAI’s announcement and the detailed VentureBeat write‑up:
-
Context window: up to 400k tokens, with 128k output. That’s enough for “hundreds of documents or large code repositories in one pass”.
-
Reasoning tokens: 5.2 embraces the same internal “reasoning” style popularized by the o‑series (o1/o3), but wrapped into standard Chat/Completions APIs instead of a separate product line.
-
Modes in ChatGPT / API:
-
GPT‑5.2 Instant – speed‑optimized; daily queries, translation, standard chat.
-
GPT‑5.2 Thinking (
gpt-5.2,gpt-5.2-chat-latest) – deeper reasoning, longer tool chains; this is the default “serious work” model. -
GPT‑5.2 Pro (
gpt-5.2-pro) – accuracy‑first, most expensive.
-
The internal design is still opaque, but the behavior is what matters: compared to GPT‑5.1, you see longer and more structured intermediate reasoning, more stable tool plans, and fewer “I don’t know, but here’s a confident guess” answers.
2.2 Where GPT‑5.2 actually stands out
From OpenAI’s own benchmarks and independent coverage:
-
Coding and bug‑fixing
-
On SWE‑bench Pro, GPT‑5.2 Thinking reportedly hits 55.6%, a new high for real‑world repository bug fixing.
-
Stronger on long‑range repo edits (multi‑file changes) and code review assistants.
-
-
General reasoning
-
ARC‑AGI‑1: GPT‑5.2 Pro passes the 90% mark (90.5%), a first for that benchmark.
-
FrontierMath: Thinking solves 40.3% of Tier 1–3 problems vs 31.0% for GPT‑5.1.
-
-
Science and knowledge
- GPQA Diamond: 93.2% for GPT‑5.2 Pro vs 88.1% for GPT‑5.1 Thinking.
-
Screen & GUI understanding
- On ScreenSpot‑Pro (GUI screenshot understanding for agentic UI use), GPT‑5.2 Thinking scores 86.3%, up from 64.2% for 5.1.
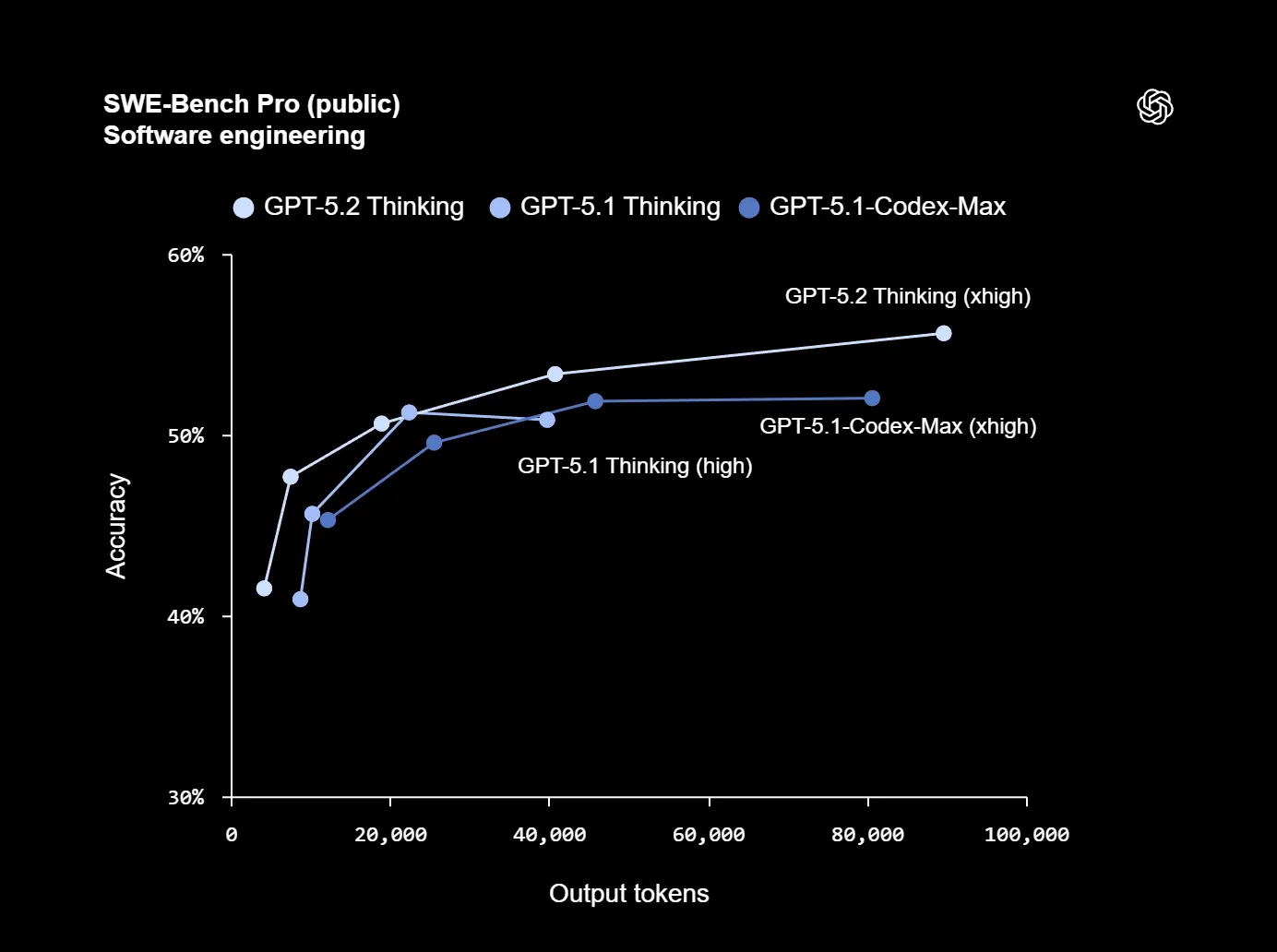
Those numbers line up with anecdotal experience: GPT‑5.2 tends to be very good at:
-
Multi‑hour agents that read, refactor and test large codebases.
-
“Heavy” documents—e.g. several legal contracts + a datasheet + a standards spec—in one context without losing track.
-
Data‑heavy reports (the 128k output limit allows entire specification documents to be generated in a single shot).
2.3 Costs and trade‑offs
Pricing from OpenAI and VentureBeat:
-
GPT‑5.2 Thinking: about $1.75 / 1M input and $14 / 1M output.
-
GPT‑5.2 Pro: $21 / 1M input and $168 / 1M output.
So:
-
If you’re building high‑value workflows (financial modelling, legal drafting, complex engineering), the extra accuracy may pay for itself.
-
For bulk workloads (high‑volume customer chats, simple summarization), cheaper models like DeepSeek‑V3.2 or Haiku 4.5 are often more cost‑effective.
GPT‑5.2 also does not introduce a new image model—OpenAI still leans on DALL·E 3 / 4o‑image for images—so if you want frontier image editing, you’ll look at Google’s Nano Banana Pro or specialized image models.
3. Gemini 3 Pro, Deep Think and Nano Banana Pro: Multimodal and agent‑first
Google’s Gemini 3 family is more than a single model; it’s an architecture for text+vision+tools+UI generation. The best public overview is the VentureBeat launch report plus Google’s own Gemini 3 blog post.
3.1 Gemini 3 Pro and Deep Think
Key points from Google and VentureBeat:
-
Variants:
-
Gemini 3 Pro – flagship general model available via the Gemini API, Google AI Studio and Vertex AI.
-
Gemini 3 Deep Think – higher‑latency, deeper‑reasoning mode, like OpenAI’s o‑series.
-
-
Benchmarks:
-
AIME 2025: 95% without tools and 100% with code execution (vs 88% for Gemini 2.5 Pro).
-
ARC‑AGI‑2: 31.1% for Pro; 45.1% for Deep Think—very high for that extremely hard, out‑of‑distribution reasoning benchmark.
-
MMMU‑Pro (multimodal academic): 81% vs previous 68%.
-
ScreenSpot‑Pro: 72.7% vs 11.4% for Gemini 2.5 Pro—huge jump for screen‑based agents.
-
-
Long‑context:
- 1M‑token context evaluations (e.g., MRCR v2, Vending‑Bench 2) show much more stable long‑horizon planning than Gemini 2.5.
-
Pricing: in preview, $2 / 1M input, $12 / 1M output up to 200k tokens, then $4 / 1M input, $18 / 1M output beyond that.
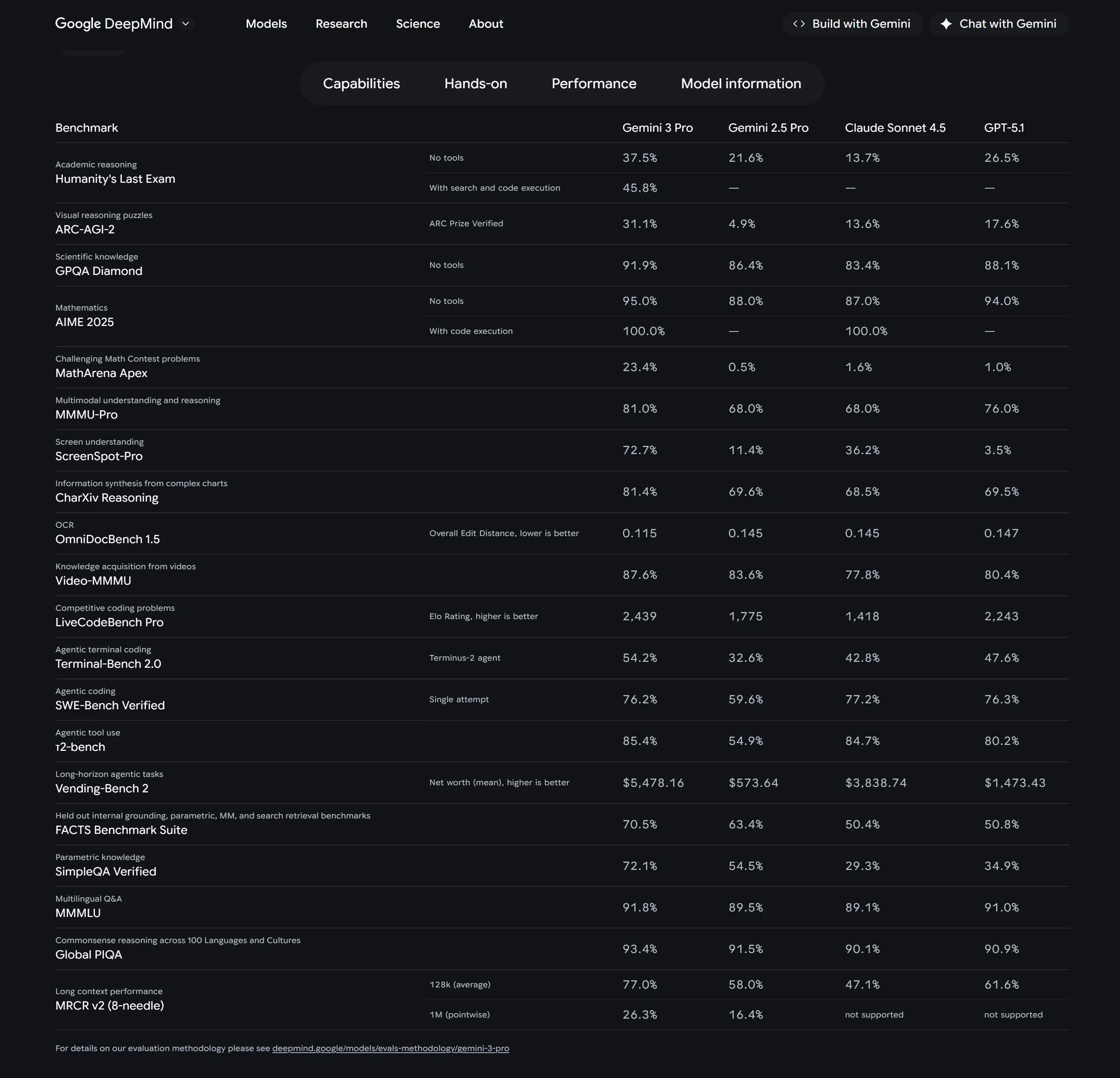
Technically, Gemini 3’s most interesting aspect isn’t just raw scores:
-
It’s designed around agents as a first‑class target:
-
Tight integration with Gemini Agent (multi‑step workflows over Gmail, Calendar, etc.).
-
New Antigravity environment, where agents get shell + browser + editor and can manage full development loops.
-
Fine‑grained controls for “thinking level” and “model resolution” in the API (depth vs cost knobs).
-
For a very detailed walk‑through of Gemini 3 Pro’s benchmark tables and behavior, see the Gemini 3 Pro deep dive.
3.2 Nano Banana Pro (Gemini 3 Image)
On the vision side, Google’s image model built on Gemini 3—often called Gemini 3 Image / Nano Banana Pro—powers Slides, Vids, and newer Workspace features. Google’s Workspace blog and the NotebookLM article note Nano Banana Pro as the backbone of new infographic and slide‑deck generation.
In practice:
-
Nano Banana Pro is tuned for structured graphics: charts, annotated diagrams, infographics, slide‑like layouts.
-
It integrates tightly with Google Docs/Slides/NotebookLM to maintain layout + text consistency, not just pretty pictures.
-
Compared with DALL·E‑class models, it’s less about “art style diversity” and more about high‑density information graphics.
A closer look at its behavior and strengths (e.g. handling complex multi‑panel diagrams from text) is in the Nano Banana Pro breakdown.
3.3 Gemini 3 in applications: NotebookLM as a case study
Google’s NotebookLM is probably the cleanest example of what you get when you design a product around an LLM from day one.
-
It started as “Project Tailwind” in 2023 and is now a full AI research assistant.
-
In 2025 Google wired NotebookLM deeply into the latest Gemini models:
-
Full 1M‑token context in chat for all plans—8× previous limits—so you can load large collections of sources.
-
Stronger retrieval and ranking for document‑grounded answers; Google reports a 50% improvement in user satisfaction for large‑source responses.
-
Audio/Video overviews, slide‑style video explanations, and, in late 2025, Nano Banana Pro‑backed infographics and slide decks.
-
-
It’s explicitly built to keep answers grounded in uploaded sources, with citations to original passages.
From a model‑selection perspective, NotebookLM is a good preview of the “LLM as long‑context research engine” pattern. An independent perspective on how this feels in use is in the NotebookLM analysis.
4. Claude 4.5 Sonnet and Opus: Agent‑friendly, conservative, and tool‑oriented
Anthropic’s Claude 4.5 family—Haiku, Sonnet and Opus—targets a different design point: long‑running, tool‑heavy agents with strong safety and conservative behavior.
The official “What’s new in Claude 4.5” page is the canonical source for features and capabilities.
4.1 Model line‑up and context
From the Anthropic docs and external comparisons:
-
Claude Haiku 4.5
-
Lightweight, very fast, low‑cost model.
-
200k‑token context; now supports extended thinking and full tool suite.
-
-
Claude Sonnet 4.5
-
“Balanced” model; Anthropic’s main coding + agents workhorse.
-
200k context, with a 1M‑token context beta also available.1
-
Extended thinking toggle for deep tasks.
-
-
Claude Opus 4.5
- Highest‑capability model, with effort controls and superior ARC‑AGI‑2 scores compared to Sonnet 4.5.
Pricing is in the Anthropic docs and third‑party comparisons; Sonnet 4.5 is around $3 / $15 per 1M tokens (in/out), Haiku 4.5 around $1 / $5, and Opus 4.5 around $5 / $25.
4.2 Technical highlights
From Anthropic’s official docs and detailed analyses:
-
Extended thinking (chain‑of‑thought as a feature)
-
Available in Sonnet 4.5, Haiku 4.5, Opus 4.5 and several previous models.
-
Can be explicitly enabled with a
thinkingparameter, with budgets for how many “thinking tokens” to allow. -
“Thinking blocks” are preserved across turns in Opus 4.5, keeping a stable internal working memory.
-
-
Context awareness
- Models track their remaining context budget across tool calls and long sessions, reducing surprise truncation.
-
Agent tooling
-
Programmatic tool calling: models can author code to orchestrate tools inside a code‑execution sandbox, avoiding round‑trips for each tool call.
-
Tool search for large tool catalogs, with regex or BM25 search to avoid loading 100+ tools into prompt context.
-
Memory tools for persistent, file‑backed state beyond the context window.
-
-
Computer use
- Computer‑use tools with a new zoom action in Opus 4.5 enable fine‑grained inspection of screen regions (e.g., small UI elements, dense dashboards).
-
Communication style
- Sonnet 4.5 is deliberately concise and fact‑focused, optimizing for progress rather than verbose reassurance.
External benchmarking (e.g. Bind’s coding comparison, independent Sonnet vs Haiku vs GPT‑5 articles) tend to agree that:
-
Haiku 4.5 is excellent for low‑latency coding and Q&A at scale.
-
Sonnet 4.5 is one of the best models for:
-
Multi‑file code refactors with tools.
-
Long‑running agents (CI assistants, automated QA, “GitOps” style agents).
-
“Computer use” tasks (OSWorld benchmarks) that involve real screens and applications.
-
-
Opus 4.5 pushes a bit further on coding benchmarks like SWE‑Bench Verified and ARC‑AGI‑2, but many teams find Sonnet’s cost/performance ratio more attractive.
Overall: if your priority is agents that must stay on task for hours, use tools reliably and explain what they’re doing, Claude Sonnet 4.5 (and Opus 4.5 when needed) are strong candidates.
5. DeepSeek‑V3.2 and R1: Open “thinking” at low cost
DeepSeek is one of the clearest demonstrations that high‑end reasoning can be made cheap.
The official API docs show the current DeepSeek‑V3.2 series and pricing.
5.1 Model variants and pricing
From DeepSeek’s own page:
-
deepseek‑chat – DeepSeek‑V3.2 (non‑thinking mode)
-
deepseek‑reasoner – DeepSeek‑V3.2 (thinking mode)
Shared properties:
-
Context length: 128k tokens.
-
Max output: default 4k (8k max) for chat; 32k (64k max) for reasoner.
-
Features: JSON output, tool calls, prefix completion, FIM completion (chat supports more features than the pure reasoner).
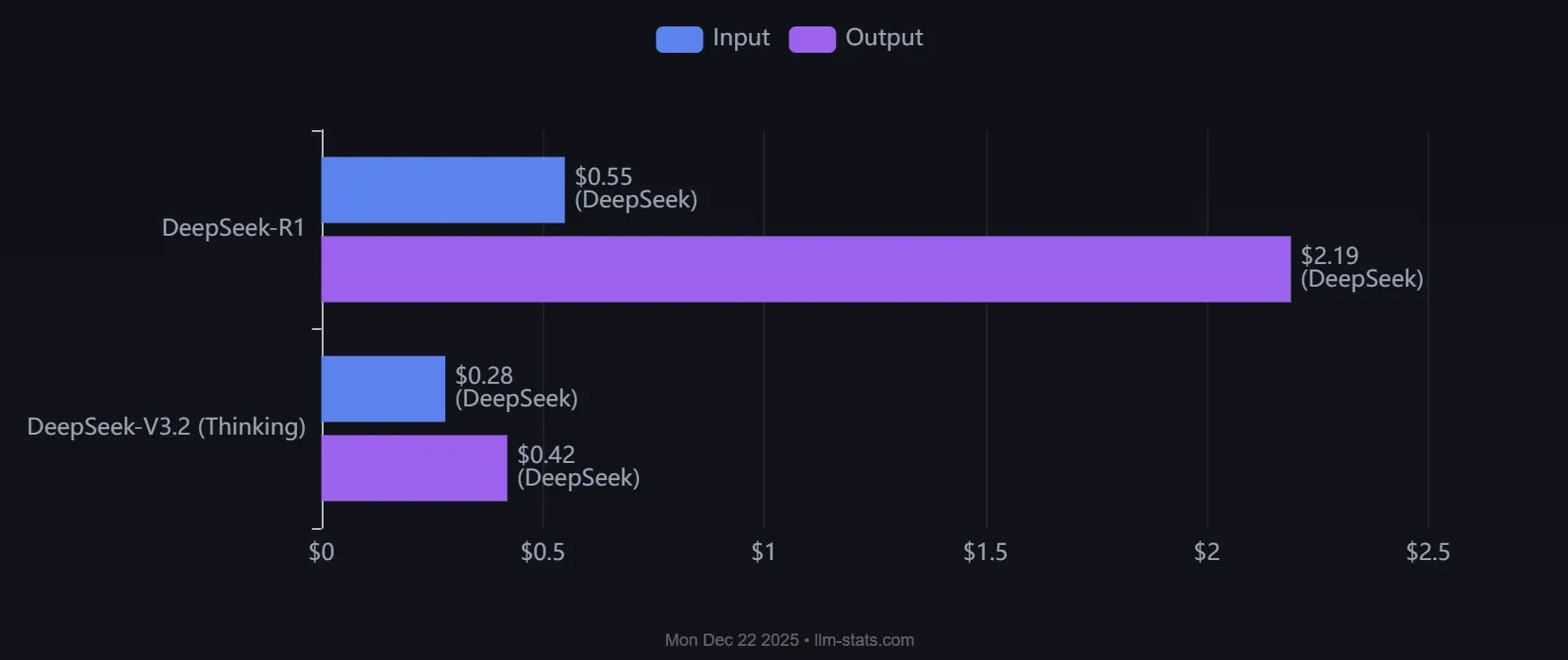
Pricing (per 1M tokens):
-
Input (cache hit): $0.028
-
Input (cache miss): $0.28
-
Output: $0.42
Those numbers are almost an order of magnitude cheaper than GPT‑5.2 Thinking or Gemini 3 Pro, while still offering strong reasoning ability.
5.2 Capabilities and usage patterns

While DeepSeek does not publish as many marketing benchmarks as US labs, independent trackers and provider comparisons (e.g. LLM‑Stats, various provider dashboards) consistently show DeepSeek‑V3.x and R1 near the top of:
-
Math benchmarks (AIME‑style).
-
Coding benchmarks (HumanEval, LiveCodeBench).
-
General reasoning tests relative to their cost tier.
The architecture appears to be a large Mixture‑of‑Experts with a thinking/non‑thinking split similar to Qwen3 and some o‑series ideas.
DeepSeek’s design encourages:
-
Using non‑thinking V3.2 for standard chat and summarization.
-
Switching to V3.2 thinking for complex problems, under explicit “thinking mode” budgets (hard limits to control run‑time and cost).
For a more pragmatic, agent‑focused view (multi‑step tasks, tool orchestration, and how V3.2 behaves under routing systems), see the DeepSeek‑V3.2 agents and benchmarks analysis.
If you need:
-
Near‑frontier reasoning,
-
But must self‑host or control costs aggressively,
DeepSeek‑V3.2 + R1 is one of the cleanest stacks available in 2025.
6. Qwen3: Open MoE with hybrid thinking and massive multilingual coverage
Alibaba’s Qwen3 is arguably the most complete open‑weight family right now: dense + MoE, thinking + non‑thinking, multilingual, strong agents.
The main sources are the official Qwen3 blog, the GitHub repo, and Alibaba’s community article.
6.1 Architecture and variants
Key facts from Alibaba and QwenLM:
-
MoE models:
-
Qwen3‑235B‑A22B – 235B parameters, 22B active (8 of 128 experts), 128k context.
-
Qwen3‑30B‑A3B – 30B total, 3B active.
-
-
Dense models: 0.6B, 1.7B, 4B, 8B, 14B, 32B with context windows up to 128k.
-
Training data: ~36T tokens (double Qwen2.5), focusing on math, code and multilingual general knowledge.
-
Multilingual: 119 languages and dialects supported, from major European and Asian languages to long‑tail dialects.
-
Licensing: Apache 2.0—permissive open‑source, commercial use allowed.2
6.2 Hybrid thinking and reasoning
Original Qwen3 introduced a hybrid thinking mode concept:
-
One model can switch between:
-
Thinking mode – long chains of thought, step‑by‑step reasoning for math and code.
-
Non‑thinking mode – direct answers for speed; toggle via
/think,/no_thinkor API flags.
-
With the later 2507 updates, Qwen is moving to separate instruct vs reasoning models (Instruct‑2507 and Thinking‑2507), improving quality at the cost of simplifying the modes.
The Qwen3‑235B‑A22B model card highlights:
-
Seamless thinking/non‑thinking switching,
-
Dedicated best‑practice configs for each mode,
-
Strong agent capabilities with the Qwen‑Agent framework.
Benchmarks summarized by Alibaba and VentureBeat show Qwen3 competing with or beating open competitors (Kimi K2, previous Qwen versions) on:
-
AIME25 (math),
-
LiveCodeBench (coding),
-
Arena‑Hard (chat),
-
Function‑calling benchmarks.
6.3 Where Qwen3 is uniquely strong
From a systems perspective, Qwen3 stands out in three places:
-
Open MoE at very high capability
-
235B / 22B active with strong reasoning scores, but with actual compute closer to a 20–30B dense model.
-
The FP8 quantized versions lower hardware requirements dramatically; VentureBeat reports 4×H100 setups and even 2×H100 with off‑loading.1
-
-
Multilingual + agent focus
-
119 languages with strong translation and instruction‑following.
-
Deep MCP integration and Qwen‑Agent for tool use.
-
-
License and ecosystem
- Apache 2.0, plus ready‑made integrations with SGLang, vLLM, Ollama, LM Studio, llama.cpp and more.
Net effect: if you want to self‑host a near‑frontier model with solid reasoning, strong multilingual support and fully open weights, Qwen3‑235B / 30B are top choices.
7. Other important families: Llama, Mistral, Grok, GLM, Kimi, MiniMax
While the headline battles are GPT vs Gemini vs Claude vs Chinese MoE, several other families matter depending on your constraints.
7.1 Meta Llama 4
Meta’s Llama 4 family (and the late‑2024/2025 Llama 3.1 / Nemotron variants) continues the “large open dense model” line. Aggregators like LLM‑Stats and blogs such as Shakudo’s Top LLMs in 2025 show:
-
Llama 4‑class models scoring competitively on MMLU, GPQA, GSM8K.
-
Good integration into commercial inference providers (AWS Bedrock, Azure, third‑party hosts).
-
Strong tooling for fine‑tuning and instruction‑specialization in enterprise environments.
If you’re committed to purely Western open weights and tight integration with mainstream cloud vendors, Llama remains a solid foundation.
7.2 Mistral and Ministral 3
Mistral’s Ministral 3 and Mistral Large 3 (675B family) add:
-
Open‑source reasoning models in the 3B, 8B, 14B range,
-
A 675B instruction model near frontier performance, hosted via Mistral’s own platform and partners.
They’re particularly attractive when:
-
You need low‑latency, small‑footprint reasoning models (8B–14B) for edge or mobile.
-
You want to combine open models with Mistral’s managed inference stack.
7.3 Grok‑4.1 and xAI
xAI’s Grok‑4.1, including Fast Reasoning and Thinking variants, has strong open‑source‑like pricing and good reasoning performance. Leaderboards frequently show Grok‑4.1 Thinking close to Gemini 3 and GPT‑5‑class models on text reasoning and coding tasks.
If cost and policy constraints push you toward non‑OpenAI/non‑Google US vendors, Grok‑4.1 deserves consideration.
7.4 GLM 4.5, Kimi K2, MiniMax M2 and other Chinese models
In addition to DeepSeek and Qwen, there’s a growing cluster of Chinese models:
-
GLM 4.5 (Zhipu AI),
-
Kimi K2 (Moonshot), including a “Thinking” variant,
-
MiniMax M2, etc.
VentureBeat and Alibaba’s community blog note that Qwen3‑235B has beaten Kimi K2 on several benchmarks while being much smaller, but Kimi still leads in some multimodal and long‑context scenarios.
The key is that Chinese labs are now:
-
Training serious reasoning models,
-
Open‑weighting many of them,
-
And pricing them very aggressively.
For teams comfortable with Chinese ecosystems and regulations, these are credible primary models, not just fallbacks.
8. How to choose: models by use‑case
Given all of the above, how do you pick in practice? Here’s a concise mapping, staying vendor‑neutral.
8.1 Deep reasoning, complex coding, long‑horizon agents
Use when:
-
You need to solve hard math, science or algorithmic problems.
-
Autonomous agents must run for hours with minimal supervision.
Candidates:
-
GPT‑5.2 Thinking / Pro – best general choice when budget allows.
-
Gemini 3 Deep Think – especially strong on ARC‑AGI‑2, AIME, multimodal science and screen‑based planning.
-
Claude Sonnet 4.5 / Opus 4.5 – when conservative, audit‑friendly tool use and stable long agents matter more than maximum raw scores.
-
Qwen3‑Thinking (235B, 30B) and DeepSeek‑V3.2 Reasoner – open‑weight alternatives if you must self‑host.
8.2 Cost‑sensitive bulk workloads (chat, summarization, moderate coding)
Use when:
- You care about cost per million tokens more than reaching every last benchmark percentile.
Candidates:
-
DeepSeek‑V3.2 (non‑thinking) – $0.28 / 1M input, $0.42 / 1M output is hard to beat.
-
Claude Haiku 4.5 – fast, cheap, surprisingly strong for code and reasoning when extended thinking is enabled.
-
Smaller Qwen3 dense models (4B–32B) – easy to fine‑tune and deploy, strong multilingual.
8.3 Long‑context research, knowledge management and doc‑grounded agents
Use when:
- You’re building something like NotebookLM: chat over large document collections with grounded answers and citations.
Candidates:
-
Gemini 3 Pro / Deep Think – for hosted long‑context + multimodal analysis (documents, screenshots, video). Exemplified in NotebookLM.
-
GPT‑5.2 Thinking – for very long reports and code+doc mixes in a single context.
-
Qwen3‑235B / 30B with YaRN – for self‑hosted, open 128k–1M‑token contexts.
-
Systems like NotebookLM show how far this can go; see the NotebookLM deep dive for product‑level implications.
8.4 Multimodal graphics, infographics and slide‑like content
Use when:
- You need charts, diagrams or slide layouts, not just generic images.
Candidates:
-
Nano Banana Pro (Gemini 3 Image) – tightly integrated with Google Slides, NotebookLM, Vids and Workspace for infographics and slide decks.
-
Gemini 3 Pro – for combined text+image+video understanding and generation.
For more examples of Nano Banana Pro’s behavior on info‑dense graphics, see the Nano Banana Pro breakdown.
8.5 On‑prem and compliance‑sensitive environments
Use when:
- Strict data‑residency and compliance rules prevent cloud‑hosted closed models.
Candidates:
-
Qwen3‑235B‑A22B / 30B, DeepSeek‑V3.2, Llama 4 family – all open‑weight and well‑documented for vLLM / SGLang / llama.cpp.
-
Qwen’s Apache 2.0 licensing and MoE architecture give a strong mix of capability and cost‑efficiency.
9. Putting it together
If you strip away marketing and focus on concrete behavior, the 2025 LLM story looks like this:
-
GPT‑5.2 and Gemini 3 sit at the top for raw reasoning and long‑horizon tasks, with different strengths:
-
GPT‑5.2: slightly more generalist, excellent at coding and professional work.
-
Gemini 3: extremely strong at ARC‑AGI‑2, mathematical reasoning, multimodal science and UI‑level agents.
-
-
Claude 4.5 Sonnet / Opus optimize for agent stability, tool use and explainability, making them attractive for production agents that must be auditable.
-
DeepSeek‑V3.2 and Qwen3 demonstrate that:
-
You no longer have to choose between open weights and serious reasoning.
-
High‑end reasoning can be done at $0.3–0.7 per million tokens if you’re willing to manage infra and tolerable quirks.
-
-
NotebookLM + Nano Banana Pro show what happens when you design a product around these models: 1M‑token contexts, grounded answers, and multi‑format outputs (text, audio, video, slides) for real research workflows.
For engineering teams, the practical pattern in 2025 is usually hybrid:
-
A “planner” model (GPT‑5.2 / Gemini 3 Deep Think / Claude Sonnet 4.5) for hard reasoning and tool orchestration.
-
One or more “executor” models (Haiku 4.5, DeepSeek‑V3.2, Qwen3‑30B) for high‑volume, low‑latency calls.
-
Domain‑tuned products (like NotebookLM) where long context and retrieval are as important as the base model.
If you share a bit about your stack—cloud vs on‑prem, language mix, budget range, and top‑priority workloads—I can sketch a concrete short‑list (e.g. “these 3 models + suggested routing logic”) tailored to your constraints, and suggest where those internal pieces like the DeepSeek‑V3.2 agents benchmarks or the GPT‑5.2 vs Gemini 3 vs Claude 4.5 comparison fit into that decision.
10. From the LLM Arms Race to Shipping Real Products with MGX
By the end of 2025, the LLM landscape looks almost complete. You have frontier models like GPT‑5.2, Gemini 3 Pro, Claude 4.5 Sonnet and Opus, aggressively priced challengers like DeepSeek V3.2, and open families such as Qwen3. Multimodal capabilities, ultra‑long context, and “thinking” modes are no longer headlines — they are the default.
That also means the real bottleneck has moved upstream. For most teams, the hard problem in 2025 is no longer “Is there a model good enough?” but “Can we reliably turn these models into a product and a business?” Choosing between GPT‑5.2 and Gemini 3 Pro for a given task matters, but so does everything around them: orchestration, data flows, evaluation, observability, and the ability to change your stack without rewriting your app every quarter.
This is exactly the gap that MetaGPT X is designed to close.
MetaGPT X treats models as interchangeable components behind a stable, product‑centric abstraction. Instead of wiring GPT‑5.2, Gemini 3 Pro, Claude 4.5, DeepSeek V3.2 or Qwen3 by hand, you describe what your product should do — research, write, execute tools, call APIs, optimize for SEO, or run multi‑step agents — and MGX composes the right graph of models and tools for you.
Under the hood, MetaGPT X combines:
-
An AI team layer that lets you define specialized agents (research, planning, writing, coding, evaluation) and coordinate them as a system rather than as a single prompt.
-
The Atoms Backend, which acts as a stateful, LLM‑native backend for your product: user profiles, documents, tools, memories, and evaluation signals live here, not sprinkled across ad‑hoc scripts.
-
Race Mode, which allows you to A/B or multi‑arm test different models — GPT‑5.2 vs Gemini 3 Pro vs Claude 4.5 Sonnet vs DeepSeek — on real traffic without touching your product code.
-
A set of focused workflows like DeepResearch, so you can ship concrete capabilities (long‑context research, structured audits) instead of reinventing them from scratch.
MetaGPT X is built for teams that want to live above that churn. You keep control over product logic and business metrics; MGX takes care of model routing, agents, evaluation, and the LLM plumbing that does not differentiate you in the market.
If 2023–2025 were the years of the model arms race, 2026 is the year of LLM business. The winners will not necessarily be the teams with access to the largest model, but the ones who can consistently turn models into shipping, resilient products.